

In this post, I will explain how the Sobel Operator edge detection algorithm works.

In order to understand how the Sobel Operator detects edges, it is important to first understand how to model an edge. Let’s take a look at that now before we examine how the Sobel Operator works.
How to Model Edges Mathematically
Consider a grayscale image that is 10 x 1 pixels. Such an image would look something like the image below:

One can clearly see in the image that there is a sudden change in the intensity in the middle of the image. This sudden change is an edge.
Now, let us draw the corresponding intensity graph of each pixel, going from left to right. We will assume that black has an intensity of -1 (the lowest intensity), and white has an intensity of 1 (the highest intensity).
Mathematically, we can detect an abrupt change in the curve above by graphing the slope of the curve (i.e. taking the first derivative at each point along the curve).
The orange curve below is the graph of the slope at each point along the pixel intensity curve. Note how the curve reaches a maximum in the middle. This peak corresponds to an edge in the original image. It is an area where the intensity (brightness) of the image changes abruptly.
However, we have run into a problem here because I have drawn a continuous curve, but pixel intensity values are discrete. Therefore, in image processing, we cannot calculate the first derivatives of an image (known as “spatial derivatives”) directly using standard calculus methods; instead we have to estimate the derivative of the image using a mathematical operation known as convolution.
Professor Andrew Ng of Stanford University has a great video on how to perform the convolution operation given an input image:
I will explain the process below.
How to Perform the Convolution Operation Given an Image as Input
To do the convolution operation, we need to use a mathematical tool called a kernel (or filter). A kernel is just a fancy name for a small matrix.
Below is an example of a kernel. This small matrix is 3×3 (3 rows and 3 columns). It happens to be the kernel used in the Sobel algorithm to calculate estimates of the derivatives in the vertical direction of an image. I will explain the Sobel algorithm later in this section.
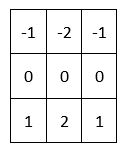
The middle cell in a kernel is known as an anchor. In this case, the anchor is 0.
The Sobel Operator, a popular edge detection algorithm, involves estimating the first derivative of an image by doing a convolution between an image (i.e. the input) and two special kernels, one to detect vertical edges and one to detect horizontal edges.
Let’s see how to estimate the first derivative of an image by doing an example convolution calculation…
Suppose we have a 6×6 pixel color image.
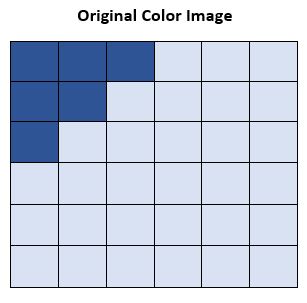
A color image has 3 channels (red, green and blue). To perform the convolution operation to detect edges, we only need one channel, so we first convert the image to grayscale. Converting the color image to grayscale is the first step of most of the edge detection algorithms, including the Sobel Operator algorithm.
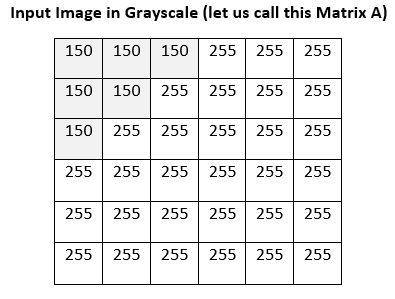
Here are what the intensity values might look like after the grayscale conversion.
Now, consider the kernel below (this happens to be the Sobel Vertical Kernel used to detect vertical edges).

To convolve matrix A with matrix B, we first overlay Matrix B on top of the upper-left portion of Matrix A and then take the element-wise product:
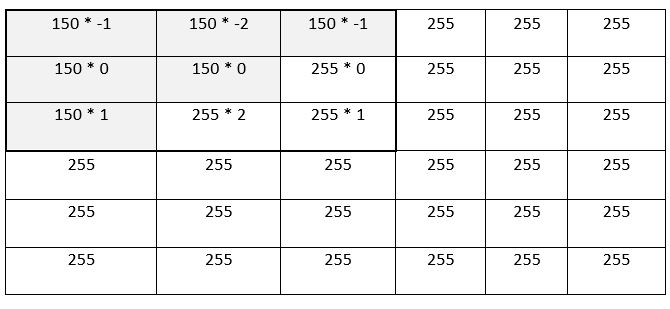
After completing the 9 multiplications, that upper-left portion becomes…
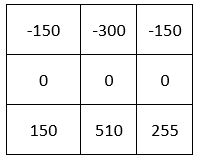
To complete the convolution operation, we add up all the numbers in the matrix above to get:
-150 + -300 + -150 + 0 + 0 + 0 + 150 + 510 + 255 = 315
The output matrix for convolving matrix A with matrix B, will be a 4×4 matrix. The value above, 315, becomes the first entry into this output matrix. You can see that 315 is a relatively large number.

We keep shifting the 3×3 kernel over the image, pixel by pixel, until we have filled up the output matrix above. That is the convolution operation.
How the Sobel Operator Works
The Sobel Operator uses kernels and the convolution operation (described above) to detect edges in an image. The algorithm works with two kernels
- A kernel to approximate intensity change in the x-direction (horizontal)
- A kernel to approximate intensity change at a pixel in the y-direction (vertical).
In mathematical jargon, “approximating the intensity change” means approximating the gradient of the intensity values at a pixel. The gradient is the multivariable generalization of the derivative or slope mentioned earlier in this discussion.
Here are the two special kernels used in the Sobel algorithm:
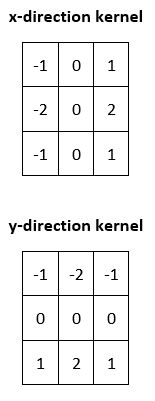
The two kernels above are convolved with each pixel in the original image to identify the regions where the change (gradient) is maximized in magnitude in the x and y directions.
Mathematical Formulation of the Sobel Operator
More formally,
- Let gradient approximations in the x-direction be denoted as Gx
- Let gradient approximations in the y-direction be denoted as Gy.
Suppose we have a source image Ii.
We want to calculate the magnitude of the gradient at a pixel (x, y), so we extract from image Ii a 3×3 matrix with pixel (x,y) as the center pixel (i.e. anchor).
The gradient approximations at pixel (x,y) given a 3×3 portion of the source image Ii are calculated as follows:
Gx = x-direction kernel * (3×3 portion of image A with (x,y) as the center cell)
Gy = y-direction kernel * (3×3 portion of image A with (x,y) as the center cell)
* above is not normal matrix multiplication. * denotes the convolution operation I described earlier in this discussion.
We then combine the values above to calculate the magnitude of the gradient at pixel (x,y):
magnitude(G) = square_root(Gx2 + Gy2)
The direction of the gradient Ɵ at pixel (x, y) is:
Ɵ = atan(Gy / Gx)
where atan is the arctangent operator.
So, in short, the algorithm goes through each pixel in an image and defines 3×3 matrices that have that pixel as the center cell (anchor pixel). Convolving these matrices with both the x and y-direction kernels yields two values, gradient approximations in the x-direction (Gx) and y-direction (Gy). We square both of these values, add them, and then take the square root of the sum to calculate the magnitude of the gradient at that pixel. Pixels that have gradients of large magnitude are likely part of an edge in an image.
Example Calculation
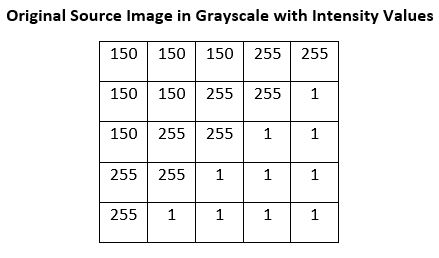
Here is an example calculation showing how to calculate the gradient approximation at a single pixel in the Sobel algorithm. We have already converted the input image into grayscale:
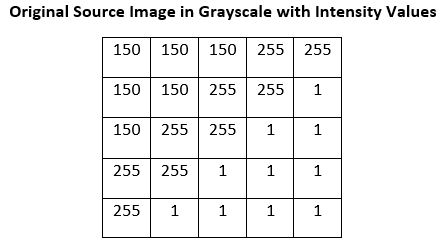
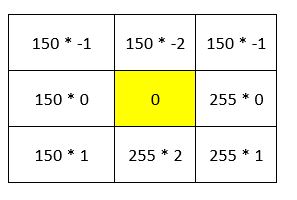
We start the calculation of the gradient in the y-direction (Gy) at the pixel in the second column and second row (marked in yellow).
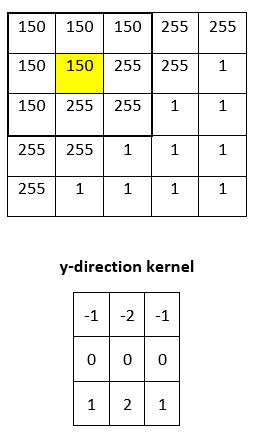
First, we convolve the selection in the original image with the y-direction kernel. The result is as follows:
Which becomes…
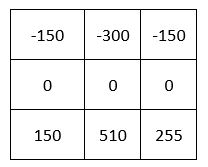
Then we add up all the numbers in the matrix above:
Gy for the pixel in row 2, column 2 is 315.
We now do a similar calculation to calculate Gx at that same pixel.The only thing that changes is the kernel that we multiply our selection by.
We start the calculation of the gradient in the x-direction (Gx) at the pixel in the second column and second row (marked in yellow).
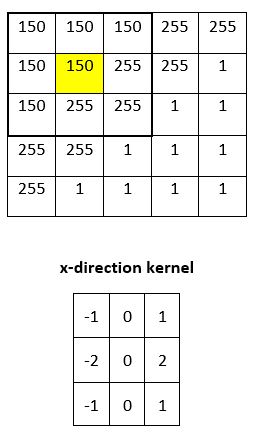
We convolve the selection in the original image with the x-direction kernel. The result is:
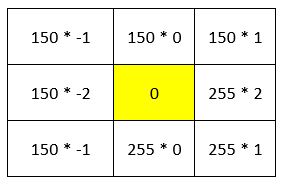
Which becomes…
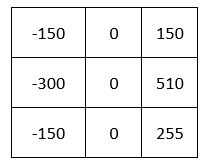
Then we add up all the numbers in the matrix above:
Gx for the pixel in row 2, column 2 is 315.
Thus, at the pixel at row 2, column 2…
Gx = 315
Gy = 315
We then combine the values above to calculate the magnitude of the gradient at pixel (x,y):
magnitude(G) = square_root(Gx2 + Gy2)
magnitude(G) = square_root(3152 + 3152)
magnitude(G) ≈ 445
This magnitude above is just our calculation for a single 3×3 region. We have to do the same thing for the other 3×3 regions in the image. And once we have done those calculations, we know that the pixels with the highest magnitude(G) are likely part of an edge.
This tutorial on GitHub has a really nice animated demonstration of the Sobel Edge Detection algorithm I explained above.
Sobel Operator Code
This tutorial on image gradients has the Python code for the Sobel Operator.









