What is ChatGPT?
ChatGPT is a large language model chatbot developed by OpenAI. It is a powerful tool that can be used for a variety of tasks. You can use it to generate text, translate languages, write different types of content, write code, and answer your questions.
Imagine a big computer with a lot of books, blog articles, form posts, academic articles, and written Internet content inside of it. ChatGPT is like a robot friend who can read all of that content and answer your questions. It can also generate new stories, poems, songs, and even code.
To use ChatGPT, you just need to talk to it like you would a friend. You can ask it questions about anything, and it will try its best to answer them. You can also give it instructions, and it will try to follow them.
For example, you could say to ChatGPT, “Tell me a story about a dragon.” And ChatGPT would tell you a story about a dragon. Or you could say, “Write me a poem about a cat.” And ChatGPT would write you a poem about a cat.
ChatGPT is still under development, but it is already amazingly good at generating human-like text. It can be a lot of fun to talk to ChatGPT, and it can also be a helpful tool for learning and creativity.
How Will ChatGPT Change the Way We Interact With and Design Robots?
Natural Language Programming
ChatGPT can be used to program robots in a natural language format. This would make it possible for people to interact with robots without having to learn complex programming languages. This would make robotics more accessible to a wider range of people, including non-technical users.
Adaptive Robots
ChatGPT can help robots to adapt to their environment and learn from their experiences. This would make robots more intelligent and capable of handling complex tasks. For example, ChatGPT could be used to train a robot to perform a new task by simply giving it a natural language description of the task.
Collaborative Robots
ChatGPT can be used to enable robots to collaborate with each other and with humans. This would make it possible to create teams of robots that can work together to solve complex problems. For example, ChatGPT could be used to detail the actions of a team of robots that are working together to build a house.
How Will ChatGPT Impact Business?
ChatGPT could lead to a wide range of new and innovative applications for robots in a variety of industries.
Here are some specific potential use cases:
Manufacturing
ChatGPT could be used to program robots to perform complex manufacturing tasks, such as assembling products or inspecting parts for defects. This could help to improve the efficiency and quality of manufacturing processes.
Logistics
ChatGPT could be used to program robots to pick and pack items in warehouses or deliver packages to customers. This could help to improve the efficiency and accuracy of logistics operations.
Healthcare
ChatGPT could be used to program robots to assist with patient care tasks, such as administering medication or transporting patients. This could help to free up nurses and doctors to focus on more complex tasks.
ChatGPT could be used to develop medical robots that can interact with patients in a more humane and empathetic way.
Education
ChatGPT could be used to create educational robots that can teach students about a variety of subjects. This could make learning more engaging and effective for students.
ChatGPT could be used to develop educational robots that can tailor their lessons to the individual needs of each student.
Customer Service
ChatGPT could be used to power customer service robots that can understand and respond to complex customer inquiries in a natural and helpful way.
Examples of Robots Using ChatGPT Today
Here are a couple of specific examples of robots using ChatGPT today:
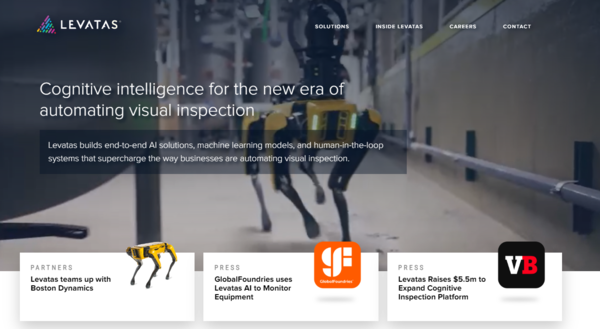
Levatas has developed a way to control Boston Dynamics Spot robots using ChatGPT voice commands. This allows operators to control the robots more naturally and hands-free, and to perform tasks that are difficult to program using traditional methods.
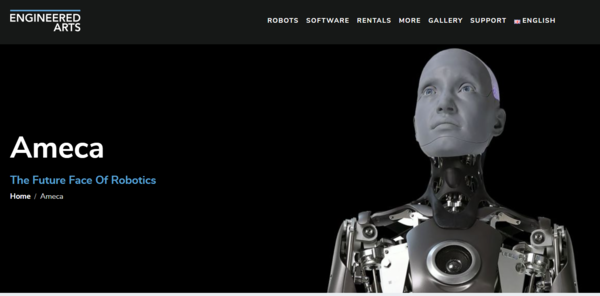
The AMECA humanoid robot has been used to demonstrate the conversational capabilities of ChatGPT. The robot can answer questions in a comprehensive and informative way, and can even engage in small talk.
ChatGPT is still under development, but it has the potential to revolutionize the field of robotics. By making robots more intelligent, adaptable, and collaborative, ChatGPT could lead to a wide range of new and innovative applications for robots in a variety of industries.
Keep building!