Good teaching is work. Great teaching is a lot of work. Mediocre teaching is no work at all.
Addison Sears-Collins (2019)
Yes, the title is provocative, but somebody had to say it. Here is a quick list why most machine learning books are a waste of time. I’ll get into each point later in this post.
Subscript and Superscript Soup
Too Much Focus on Irrelevant Minutiae
Teaching to the Tools Instead of the Problem
No Common Language
Author Has No Training on How to Teach
Using Words Like “Basically”, “Simple”, and “Easy”
Show Me Don’t Tell Me
Here is What Well Written Textbooks Look Like
Most of the “introductory” machine learning books (textbooks, especially) suck. While the subject matter in these books is supposed to be introductory, the way in which concepts are explained is not introductory at all. Simple concepts are often explained with such complex jargon and mathematical symbol soup that the underlying ideas get totally lost.
If you want to see mental masturbation at its finest, just pick up any of the popular machine learning textbooks used in machine learning courses at colleges and universities around the world.
So many of these machine learning textbooks spend pages and pages explaining machine learning without actually doing machine learning with step-by-step fully worked real-world examples (I presume because the publisher wants to limit the page count). It is kind of like learning how to play tennis by having someone explain to you how to play tennis vs. getting out there on the court and actually playing!
While reading these books, I always find myself asking these questions:
Why write an introductory book if the explanations are so convoluted that only an expert can understand?
Why ask end-of-chapter questions and provide no answer key?
Why provide no step-by-step practice with real-world examples?
Feedback and deliberate practice is a critical part of building confidence as you learn a new skill. Most of the “introduction” to machine learning books lose sight of this concept. Authors need to realize that you need to start with teeny tiny baby steps when you are writing for beginners.
Subscript and Superscript Soup
Take a look at this excerpt from a popular Introduction to Machine Learning textbook where the author attempts to explain logistic regression.
This example hits on one of my biggest annoyances about machine learning books. The algorithms and mathematical equations contain so many variables, subscripts, and superscripts that you need to make a glossary on a separate sheet of paper just to keep track of it all because it would be utterly impossible to retain everything in your head while trying to decipher the points the author is trying to make. This kind of practice gets in the way of learning as well as your ability to see the big picture.
Most of these “introduction” to machine learning books are written for people who already have a deep expertise in the subject. The subscript and superscript soup present in these books are as understandable to me as Ancient Greek.
What the heck is this guy talking about? I had to double check the preface to see if this book was written for beginners or experts (i.e. it was written for beginners). To the average undergrad who wants to go out and get a job applying machine learning to real-world problems, how important is it to know all these mathematical details upfront?
Answer: Not very important. Rarely will you ever need to know these details, and if you do, just look them up. Most textbooks focus way too much on the minutiae (as if they are writing an academic research paper) and not enough on how to apply this knowledge to solve real-world problems.
At no point do these authors convey:
Why does knowing this matter?
What value does knowing this have on a real-world application as well as my ability to get and retain a job in this field. Most beginners don’t want to go on to get PhDs and do research. Some do, but most of the readers do not.
Teaching to the Tools Instead of the Problem
Machine learning textbooks need to teach to the problem, not to the tools and the underlying mathematics. They need to first tell you why something is important. The easiest way to do this is to explain a concept by starting with a real-world problem.
Most textbooks, instead, do it the other way around. They teach you the intricate details of the tool in isolation, teach you some proof, and then (in rare cases), apply the concept to a problem (a problem which almost never resembles the types of problems you would face in the real world at a job).
Authors need to show readers how machine learning fits into the big picture (i.e. the other tools a beginner might already be familiar with, like statistics or data analysis). At the end of the day, machine learning is just a tool. It is not a panacea.
It is just a tool, just like the World Wide Web is a tool…just like a programming language like Python is a tool…or just like Microsoft Excel is a tool.
Machine Learning is to an engineer what a wrench is to a mechanic. A mechanic does not need to know how to build a wrench in order to use it. He just needs to know how to use it to solve a problem. The vast majority of people will not need to know the underlying proofs and mathematics at such a detailed level in order to succeed in the workplace (unless you become a researcher, in that case, you will be trying to build a better wrench).
Machine Learning is a tool in the toolbox
Machine learning textbooks need to start with a real-world problem, then work through that problem, set-by-step, and explain the mathematics on an as-needed basis, not just throw it on the page for the sake of pretending to be mathematically rigorous.
I don’t need to know how an internal combustion engine is built to be an awesome driver, and most companies will hire you based on your problem-solving ability, not on your ability to write proofs of off-the-shelf algorithms…so problem solving is what books need to focus on.
No Common Language
It does not help that there is no common language in machine learning. There are sometimes a dozen different ways to say the same thing (feature, attribute, predictor, x-variables, independent variables, etc.) or (target, class, response variable, y-variable, hypothesis). These multiple ways of saying the same thing make it totally confusing for a beginner, and rarely do authors point out the fact that there are a myriad of ways of saying the same thing.
Author Has No Training on How to Teach
Many of these authors are accustomed to writing for an expert audience (via academic research papers) and have not properly developed the skill of breaking down complex subject matter into easy-to-understand, digestible bite-sized pieces that would be understandable by a competent beginner.
Elementary and high school teachers must get a degree or diploma in teaching. They have to endure hundreds of hours of instruction on how to teach and how to deal with different learning styles. Most machine learning textbook authors have not had this training.
I find that the best teachers of a subject are often students who are one step removed from having learned the subject. It is fresh in their minds, and they still remember what it is like to be a beginner.
Using Words Like “Basically”, “Simple”, and “Easy”
A favorite of machine learning textbook authors it to make the assumption that the reader already understands a “simple” concept that’s necessary to understand the new topic. This is frustrating for someone new.
So many of these textbooks use terms like “simple,” “straightforward,” “easy,” “obvious,” and “basically,” which hurts a beginner’s confidence if he is not easily able to grasp the material. This is a huge pet peeve of mine. Words like these have no place in a book claiming to be an “introduction.”
You’re trying to climb the machine learning mountain. The author is already at the top of the mountain. The author forgot how hard the struggle was to get to the top. The author forgot what it is like to even take the first step because it has been so long. It all seems easy after you’ve been there, done that.
It would be like Michael Jordan teaching someone how to play basketball. Some things are so intuitive and second nature to him that, although he is the best basketball player that ever lived, he might not be the best one to teach it because he is so far removed from what it was like as a beginner, learning the basics, when even the smallest steps are difficult and not second nature.
Similarly, you might know how to ride a bicycle really well. However, try to teach someone else how to ride a bicycle. You will notice that teaching someone how to ride a bike is different from being a really good bike rider. In order to teach someone how to ride a bike, you have to take what you know and break it down into teeny tiny parts. The ability to do this well is a skill in and of itself…one that takes time and practice to get good at.
When you learn something, and especially if it is something you’ve spent decades immersed in, it’s intuition to you. Most machine learning books are especially bad about this. They just assume that you understand exactly what is going on. They do not explain. It was just “if this, then that.” They speak in generalities and hand-wavy language when the beginner needs step-by-step detail. They use machine learning and math to explain machine learning and math.
They do not realize that in order to teach someone something, it is best to tie the new concept to a concept that the beginner might already be familiar with.
Again, the best teachers in my experience are those that are one step removed from learning a subject as they have the knowledge fresh in their mind and remember clearly what it is like to be a beginner.
Show Me Don’t Tell Me
Authors need to stop introducing a new concept by explaining it. Instead, they need to use the following teaching aids:
Analogies: Connect the current knowledge to previous knowledge that most beginners would have.
Pictures and Diagrams: Draw a picture to help me visualize the concept.
Real-world Examples: Why does this concept matter? Show me a real-world example of this concept in practice, solving an actual problem. Tell me a story.
Layman’s Terms: Explain a term in basic plain language. Act as if you are explaining a concept to a five-year-old child.
Here is What Well Written Textbooks Look Like
Here is what a well written textbooks for beginners should look like. Consider these textbooks among the GOATs (i.e. greatest of all time) of textbooks:
We now need to make sure we have all the software packages installed. Check to see if you have OpenCV installed on your machine. If you are using Anaconda, you can type:
conda install -c conda-forge opencv
Alternatively, you can type:
pip install opencv-python
Make sure you have NumPy installed, a scientific computing library for Python.
If you’re using Anaconda, you can type:
conda install numpy
Alternatively, you can type:
pip install numpy
Write the Code
Open up a new Python file called numpy_array_creation.py.
Here is the full code:
# Project: How To Create a NumPy Array
# Author: Addison Sears-Collins
# Date created: February 24, 2021
# Description: Basics of using the NumPy library
import numpy as np # Import the NumPy library
# Create and print a two dimensional array with 7 rows and 4 columns
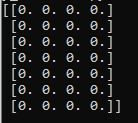
my_array = np.zeros((7,4))
#print(my_array)
# Print the data type
#print(my_array.dtype)
# Print the dimensions of the array
#print(my_array.shape)
#print("Number of rows in the array = {}".format(my_array.shape[0]))
#print("Number of columns in the array = {}".format(my_array.shape[1]))
# Create an array of ones that contains 8-bit unsigned integers
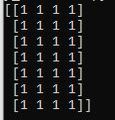
my_array_ones = np.ones((7,4), dtype=np.uint8)
#print(my_array_ones)
# Create an array of random numbers
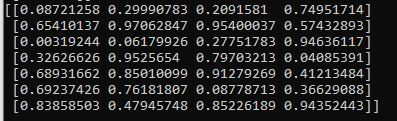
my_array_random_nums = np.random.rand(7,4)
#print(my_array_random_nums)
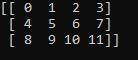
# Create a 4x3 two-dimensional array (i.e. a matrix)
my_2d_array = np.array([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
#print(my_2d_array)
# Extract the value from the matrix on row 3, column 2 (i.e. the 9)
#print(my_2d_array[2,1])
Code Output
# Create and print a two dimensional array with 7 rows and 4 columns
my_array = np.zeros((7,4))
print(my_array)
# Print the data type
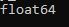
print(my_array.dtype)
# Print the dimensions of the array
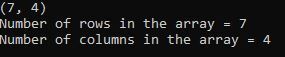
print(my_array.shape)
print("Number of rows in the array = {}".format(my_array.shape[0]))
print("Number of columns in the array = {}".format(my_array.shape[1]))
# Create an array of ones that contains 8-bit unsigned integers
my_array_ones = np.ones((7,4), dtype=np.uint8)
print(my_array_ones)
# Create an array of random numbers
my_array_random_nums = np.random.rand(7,4)
print(my_array_random_nums)