
In this tutorial, we will learn how to create a publisher and a subscriber node in ROS2 (Foxy Fitzroy…the latest version of ROS2) from scratch.
Requirements
We’ll create three separate nodes:
- A node that publishes the coordinates of an object detected by a fictitious camera (in reality, we’ll just publish random (x,y) coordinates of an object to a ROS2 topic).
- A program that converts the coordinates of the object from the camera reference frame to the (fictitious) robotic arm base frame.
- A node that publishes the coordinates of the object with respect to the robotic arm base frame.
I thought this example would be more fun and realistic than the “hello world” example commonly used to teach people how to write ROS subscriber and publisher nodes.
Real-World Applications

A real-world application of what we’ll accomplish in this tutorial would be a pick and place task where a robotic arm needs to pick up an object from one location and place it in another (e.g. factory, warehouse, etc.).
With some modifications to the code in this tutorial, you can create a complete ROS2-powered robotic system that can:
- Detect an object with a camera such as a Raspberry Pi camera (Check out this post to see how to do that).
- Move a robotic arm to the location of the object automatically (Check out this post to see how to do that).
- Pick up the object and place it in another location.
To complete such a project, you would need to write one more node, a node (i.e. a single Arduino sketch) for your Arduino to control the motors of the robotic arm. This node would need to:
- Subscribe to the coordinates of the object.
- Convert those coordinates into servo motor angles using inverse kinematics.
- Move the robotic arm to the location of the object to pick it up.
Prerequisites
- You have ROS2 installed and working in a Linux environment.
- You know how to setup a basic ROS2 project (Optional).
- You know how to perform coordinate transformations (Optional).
Source Your ROS2 Installation
Open a new terminal window.
Open your .bashrc file.
gedit ~/.bashrc
If you don’t have gedit installed, be sure to install it before you run the command above.
sudo apt-get install gedit
Add this line of code to the very bottom of the file (Note: The line might already be there. If so, please ignore these steps).
source /opt/ros/foxy/setup.bash
You now don’t have to source your ROS2 installation every time you open a new terminal window.
Save the file, and close it.
Let’s create a workspace directory.
mkdir -p ~/camera_to_robot_base_frame_ws/src
Open your .bashrc file.
gedit ~/.bashrc
Add this line of code to the very bottom of the .bashrc file.
source ~/camera_to_robot_base_frame_ws/install/setup.bash
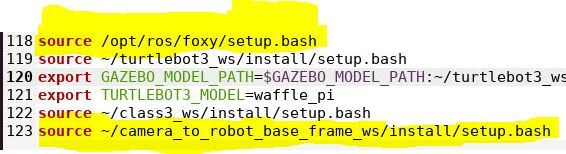
Save the file and close it.
Create a Package
Open a new terminal window, and type:
cd ~/camera_to_robot_base_frame_ws/src
Now let’s create a ROS package.
Type this command:
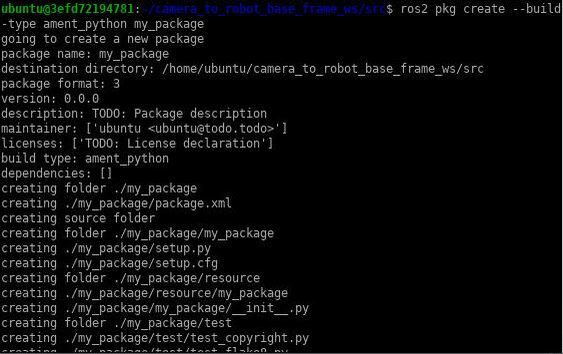
ros2 pkg create --build-type ament_python my_package
Your package named my_package has now been created.
Build Your Package
Return to the root of your workspace:
cd ~/camera_to_robot_base_frame_ws/
Build all packages in the workspace.
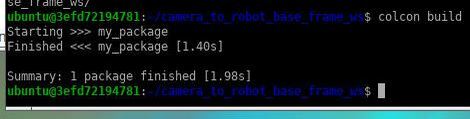
colcon build
Write Node(s)
Open a new terminal window.
Move to the camera_to_robot_base_frame_ws/src/my_package/my_package folder.
cd camera_to_robot_base_frame_ws/src/my_package/my_package
Write this program, and add it to this folder you’re currently in. The name of this file is camera_publisher.py.
This code generates random object coordinates (i.e. x and y location). In a real-world scenario, you would be detecting an object with a camera and then publishing those coordinates to a ROS2 topic.
gedit camera_publisher.py
''' ####################
Detect an object in a video stream and publish its coordinates
from the perspective of the camera (i.e. camera reference frame)
Note: You don't need a camera to run this node. This node just demonstrates how to create
a publisher node in ROS2 (i.e. how to publish data to a topic in ROS2).
-------
Publish the coordinates of the centroid of an object to a topic:
/pos_in_cam_frame – The position of the center of an object in centimeter coordinates
==================================
Author: Addison Sears-Collins
Date: September 28, 2020
#################### '''
import rclpy # Import the ROS client library for Python
from rclpy.node import Node # Enables the use of rclpy's Node class
from std_msgs.msg import Float64MultiArray # Enable use of the std_msgs/Float64MultiArray message type
import numpy as np # NumPy Python library
import random # Python library to generate random numbers
class CameraPublisher(Node):
"""
Create a CameraPublisher class, which is a subclass of the Node class.
The class publishes the position of an object every 3 seconds.
The position of the object are the x and y coordinates with respect to
the camera frame.
"""
def __init__(self):
"""
Class constructor to set up the node
"""
# Initiate the Node class's constructor and give it a name
super().__init__('camera_publisher')
# Create publisher(s)
# This node publishes the position of an object every 3 seconds.
# Maximum queue size of 10.
self.publisher_position_cam_frame = self.create_publisher(Float64MultiArray, '/pos_in_cam_frame', 10)
# 3 seconds
timer_period = 3.0
self.timer = self.create_timer(timer_period, self.get_coordinates_of_object)
self.i = 0 # Initialize a counter variable
# Centimeter to pixel conversion factor
# Assume we measure 36.0 cm across the width of the field of view of the camera.
# Assume camera is 640 pixels in width and 480 pixels in height
self.CM_TO_PIXEL = 36.0 / 640
def get_coordinates_of_object(self):
"""
Callback function.
This function gets called every 3 seconds.
We locate an object using the camera and then publish its coordinates to ROS2 topics.
"""
# Center of the bounding box that encloses the detected object.
# This is in pixel coordinates.
# Since we don't have an actual camera and an object to detect,
# we generate random pixel locations.
# Assume x (width) can go from 0 to 640 pixels, and y (height) can go from 0 to 480 pixels
x = random.randint(250,450) # Generate a random integer from 250 to 450 (inclusive)
y = random.randint(250,450) # Generate a random integer from 250 to 450 (inclusive)
# Calculate the center of the object in centimeter coordinates
# instead of pixel coordinates
x_cm = x * self.CM_TO_PIXEL
y_cm = y * self.CM_TO_PIXEL
# Store the position of the object in a NumPy array
object_position = [x_cm, y_cm]
# Publish the coordinates to the topic
self.publish_coordinates(object_position)
# Increment counter variable
self.i += 1
def publish_coordinates(self,position):
"""
Publish the coordinates of the object to ROS2 topics
:param: The position of the object in centimeter coordinates [x , y]
"""
msg = Float64MultiArray() # Create a message of this type
msg.data = position # Store the x and y coordinates of the object
self.publisher_position_cam_frame.publish(msg) # Publish the position to the topic
def main(args=None):
# Initialize the rclpy library
rclpy.init(args=args)
# Create the node
camera_publisher = CameraPublisher()
# Spin the node so the callback function is called.
# Publish any pending messages to the topics.
rclpy.spin(camera_publisher)
# Destroy the node explicitly
# (optional - otherwise it will be done automatically
# when the garbage collector destroys the node object)
camera_publisher.destroy_node()
# Shutdown the ROS client library for Python
rclpy.shutdown()
if __name__ == '__main__':
main()
Save the file and close it.
Now change the permissions on the file.
chmod +x camera_publisher.py
Let’s add a program (this isn’t a ROS2 node…it’s just a helper program that performs calculations) that will be responsible for converting the object’s coordinates from the camera reference frame to the to robot base frame. We’ll call it coordinate_transform.py.
gedit coordinate_transform.py
''' ####################
Convert camera coordinates to robot base frame coordinates
==================================
Author: Addison Sears-Collins
Date: September 28, 2020
#################### '''
import numpy as np
import random # Python library to generate random numbers
class CoordinateConversion(object):
"""
Parent class for coordinate conversions
All child classes must implement the convert function.
Every class in Python is descended from the object class
class CoordinateConversion == class CoordinateConversion(object)
This class is a superclass, a general class from which
more specialized classes (e.g. CameraToRobotBaseConversion) can be defined.
"""
def convert(self, frame_coordinates):
"""
Convert between coordinate frames
Input
:param frame_coordinates: Coordinates of the object in a reference frame (x, y, z, 1)
Output
:return: new_frame_coordinates: Coordinates of the object in a new reference frame (x, y, z, 1)
"""
# Any subclasses that inherit this superclass CoordinateConversion must implement this method.
raise NotImplementedError
class CameraToRobotBaseConversion(CoordinateConversion):
"""
Convert camera coordinates to robot base frame coordinates
This class is a subclass that inherits the methods from the CoordinateConversion class.
"""
def __init__(self,rot_angle,x_disp,y_disp,z_disp):
"""
Constructor for the CameraToRobotBaseConversion class. Sets the properties.
Input
:param rot_angle: Angle between axes in degrees
:param x_disp: Displacement between coordinate frames in the x direction in centimeters
:param y_disp: Displacement between coordinate frames in the y direction in centimeters
:param z_disp: Displacement between coordinate frames in the z direction in centimeters
"""
self.angle = np.deg2rad(rot_angle) # Convert degrees to radians
self.X = x_disp
self.Y = y_disp
self.Z = z_disp
def convert(self, frame_coordinates):
"""
Convert camera coordinates to robot base frame coordinates
Input
:param frame_coordinates: Coordinates of the object in the camera reference frame (x, y, z, 1) in centimeters
Output
:return: new_frame_coordinates: Coordinates of the object in the robot base reference frame (x, y, z, 1) in centimeters
"""
# Define the rotation matrix from the robotic base frame (frame 0)
# to the camera frame (frame c).
rot_mat_0_c = np.array([[1, 0, 0],
[0, np.cos(self.angle), -np.sin(self.angle)],
[0, np.sin(self.angle), np.cos(self.angle)]])
# Define the displacement vector from frame 0 to frame c
disp_vec_0_c = np.array([[self.X],
[self.Y],
[self.Z]])
# Row vector for bottom of homogeneous transformation matrix
extra_row_homgen = np.array([[0, 0, 0, 1]])
# Create the homogeneous transformation matrix from frame 0 to frame c
homgen_0_c = np.concatenate((rot_mat_0_c, disp_vec_0_c), axis=1) # side by side
homgen_0_c = np.concatenate((homgen_0_c, extra_row_homgen), axis=0) # one above the other
# Coordinates of the object in base reference frame
new_frame_coordinates = homgen_0_c @ frame_coordinates
return new_frame_coordinates
def main():
"""
This code is used to test the methods implemented above.
"""
# Define the displacement from frame base frame of robot to camera frame in centimeters
x_disp = -17.8
y_disp = 24.4
z_disp = 0.0
rot_angle = 180 # angle between axes in degrees
# Create a CameraToRobotBaseConversion object
cam_to_robo = CameraToRobotBaseConversion(rot_angle, x_disp, y_disp, z_disp)
# Centimeter to pixel conversion factor
# I measured 36.0 cm across the width of the field of view of the camera.
CM_TO_PIXEL = 36.0 / 640
print(f'Detecting an object for 3 seconds')
dt = 0.1 # Time interval
t = 0 # Set starting time
while t<3:
t = t + dt
# This is in pixel coordinates.
# Since we don't have an actual camera and an object to detect,
# we generate random pixel locations.
# Assume x (width) can go from 0 to 640 pixels, and y (height) can go from 0 to 480 pixels
x = random.randint(250,450) # Generate a random integer from 250 to 450 (inclusive)
y = random.randint(250,450) # Generate a random integer from 250 to 450 (inclusive)
# Calculate the center of the object in centimeter coordinates
# instead of pixel coordinates
x_cm = x * CM_TO_PIXEL
y_cm = y * CM_TO_PIXEL
# Coordinates of the object in the camera reference frame
cam_ref_coord = np.array([[x_cm],
[y_cm],
[0.0],
[1]])
robot_base_frame_coord = cam_to_robo.convert(cam_ref_coord) # Return robot base frame coordinates
text = "x: " + str(robot_base_frame_coord[0][0]) + ", y: " + str(robot_base_frame_coord[1][0])
print(f'{t}:{text}') # Display time stamp and coordinates
if __name__ == '__main__':
main()
Save the file and close it.
Now change the permissions on the file.
chmod +x coordinate_transform.py
Now we’ll add one more node. This node will be responsible for receiving the coordinates of an object in the camera reference frame (these coordinates are published to the ‘/pos_in_cam_frame’ topic by camera_publisher.py), using coordinate_transform.py to convert those coordinates to the robotic arm base frame, and finally publishing these transformed coordinates to the ‘/pos_in_robot_base_frame’ topic.
Name this node robotic_arm_publishing_subscriber.py.
gedit robotic_arm_publishing_subscriber.py
''' ####################
Receive (i.e. subscribe) coordinates of an object in the camera reference frame, and
publish those coordinates in the robotic arm base frame.
-------
Publish the coordinates of the centroid of an object to topic:
/pos_in_robot_base_frame – The x and y position of the center of an object in centimeter coordinates
==================================
Author: Addison Sears-Collins
Date: September 28, 2020
#################### '''
import rclpy # Import the ROS client library for Python
from rclpy.node import Node # Enables the use of rclpy's Node class
from std_msgs.msg import Float64MultiArray # Enable use of the std_msgs/Float64MultiArray message type
import numpy as np # NumPy Python library
from .coordinate_transform import CameraToRobotBaseConversion
class PublishingSubscriber(Node):
"""
Create a PublishingSubscriber class, which is a subclass of the Node class.
This class subscribes to the x and y coordinates of an object in the camera reference frame.
The class then publishes the x and y coordinates of the object in the robot base frame.
"""
def __init__(self):
"""
Class constructor to set up the node
"""
# Initiate the Node class's constructor and give it a name
super().__init__('publishing_subscriber')
# Create subscriber(s)
# The node subscribes to messages of type std_msgs/Float64MultiArray, over a topic named:
# /pos_in_cam_frame
# The callback function is called as soon as a message is received.
# The maximum number of queued messages is 10.
self.subscription_1 = self.create_subscription(
Float64MultiArray,
'/pos_in_cam_frame',
self.pos_received,
10)
self.subscription_1 # prevent unused variable warning
# Create publisher(s)
# This node publishes the position in robot frame coordinates.
# Maximum queue size of 10.
self.publisher_pos_robot_frame = self.create_publisher(Float64MultiArray, '/pos_in_robot_base_frame', 10)
# Define the displacement from frame base frame of robot to camera frame in centimeters
x_disp = -17.8
y_disp = 24.4
z_disp = 0.0
rot_angle = 180 # angle between axes in degrees
# Create a CameraToRobotBaseConversion object
self.cam_to_robo = CameraToRobotBaseConversion(rot_angle, x_disp, y_disp, z_disp)
def pos_received(self, msg):
"""
Callback function.
This function gets called as soon as the position of the object is received.
:param: msg is of type std_msgs/Float64MultiArray
"""
object_position = msg.data
# Coordinates of the object in the camera reference frame in centimeters
cam_ref_coord = np.array([[object_position[0]],
[object_position[1]],
[0.0],
[1]])
robot_base_frame_coord = self.cam_to_robo.convert(cam_ref_coord) # Return robot base frame coordinates
# Capture the object's desired position (x, y)
object_position = [robot_base_frame_coord[0][0], robot_base_frame_coord[1][0]]
# Publish the coordinates to the topics
self.publish_position(object_position)
def publish_position(self,object_position):
"""
Publish the coordinates of the object with respect to the robot base frame.
:param: object position [x, y]
"""
msg = Float64MultiArray() # Create a message of this type
msg.data = object_position # Store the object's position
self.publisher_pos_robot_frame.publish(msg) # Publish the position to the topic
def main(args=None):
# Initialize the rclpy library
rclpy.init(args=args)
# Create the node
publishing_subscriber = PublishingSubscriber()
# Spin the node so the callback function is called.
# Pull messages from any topics this node is subscribed to.
# Publish any pending messages to the topics.
rclpy.spin(publishing_subscriber)
# Destroy the node explicitly
# (optional - otherwise it will be done automatically
# when the garbage collector destroys the node object)
publishing_subscriber.destroy_node()
# Shutdown the ROS client library for Python
rclpy.shutdown()
if __name__ == '__main__':
main()
Save the file and close it.
Now change the permissions on the file.
chmod +x robotic_arm_publishing_subscriber.py
Add Dependencies
Navigate one level back.
cd ..
You are now in the camera_to_robot_base_frame_ws/src/my_package/ directory.
Type
ls
You should see the setup.py, setup.cfg, and package.xml files.
Open package.xml with your text editor.
gedit package.xml
Fill in the <description>, <maintainer>, and <license> tags.
<name>my_package</name>
<version>0.0.0</version>
<description>Converts camera coordinates to robotic arm base frame coordinates</description>
<maintainer email="example@automaticaddison.com">Addison Sears-Collins</maintainer>
<license>All Rights Reserved.</license>
Add a new line after the ament_python build_type dependency, and add the following dependencies which will correspond to other packages the packages in this workspace needs (this will be in your node’s import statements):
<exec_depend>rclpy</exec_depend><exec_depend>std_msgs</exec_depend>This let’s the system know that this package needs the rclpy and std_msgs packages when its code is executed.
Save the file and close it.
Add an Entry Point
Now we need to add the entry points for the node(s) by opening the setup.py file.
gedit setup.py
Make sure to modify the entry_points block of code so that it looks like this:
entry_points={
'console_scripts': [
'camera_publisher = my_package.camera_publisher:main',
'robotic_arm_publishing_subscriber = my_package.robotic_arm_publishing_subscriber:main',
],
},
Save setup.py and close it.
Check for Missing Dependencies
Check for any missing dependencies before you build the package.
Move to your workspace folder.
cd ~/camera_to_robot_base_frame_ws
Run the following command:
rosdep install -i --from-path src --rosdistro foxy -y
I get a message that says:
“#All required rosdeps installed successfully”
Build and Run
Now, build your package by first moving to the src folder.
cd src
Then build the package.
colcon build
You should get a message that says:
“Summary: 1 package finished [<time it took in seconds>]”
If you get errors, go to your Python programs and check for errors. Python is sensitive to indentation (tabs and spaces), so make sure the spacing of the code is correct (go one line at a time through the code).
The programs are located in this folder.
cd camera_to_robot_base_frame_ws/src/my_package/my_package
After you make changes, build the package again.
cd ~/camera_to_robot_base_frame_ws
colcon build
You should see this message when everything build successfully:
Open a new terminal tab.
Run the nodes:
ros2 run my_package camera_publisher
In another terminal tab:
ros2 run robotic_arm_publishing_subscriber
Open a new terminal tab, and move to the root directory of the workspace.
cd ~/camera_to_robot_base_frame_ws
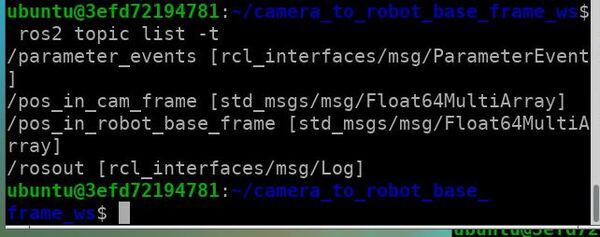
List the active topics.
ros2 topic list -t
To listen to any topic, type:
ros2 topic echo /topic_name
Where you replace “/topic_name” with the name of the topic.
For example:
ros2 topic echo /pos_in_cam_frame
You should see the (x, y) coordinates of the object (in the camera reference frame) printed to the screen.
In another terminal, you can type:
ros2 topic echo /pos_in_robot_base_frame
You should see the (x, y) coordinates of the object (in the robot base frame) printed to the screen.
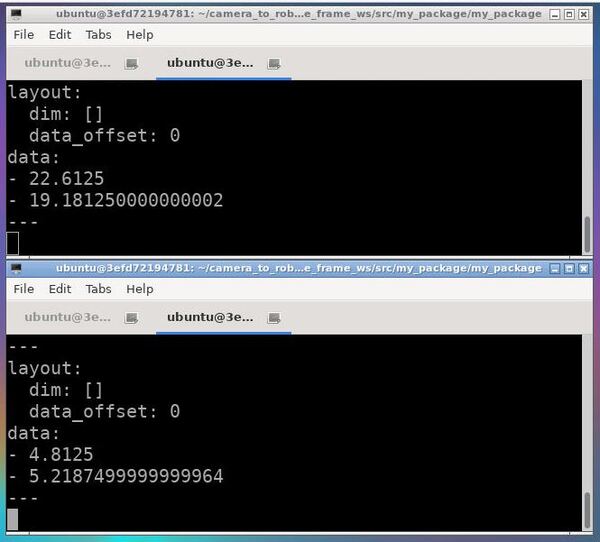
Here is how my terminal windows look. The camera coordinates in centimeters are on top, and the robot base frame coordinates are on the bottom.
When you’ve had enough, type Ctrl+C in each terminal tab to stop the nodes from spinning.
Zip the Workspace for Distribution
If you ever want to zip the whole workspace and send it to someone, open a new terminal window.
Move to the directory containing your workspace.
cd ~/camera_to_robot_base_frame_ws
cd ..
zip -r camera_to_robot_base_frame_ws.zip camera_to_robot_base_frame_ws
The syntax is:
zip -r <filename.zip> <foldername>

