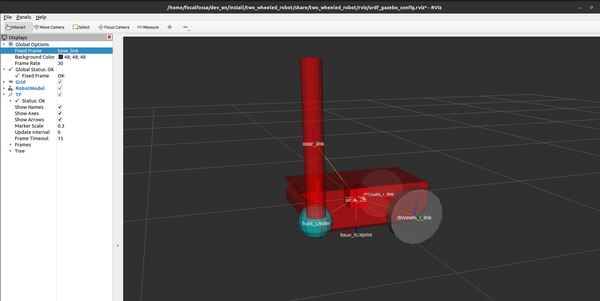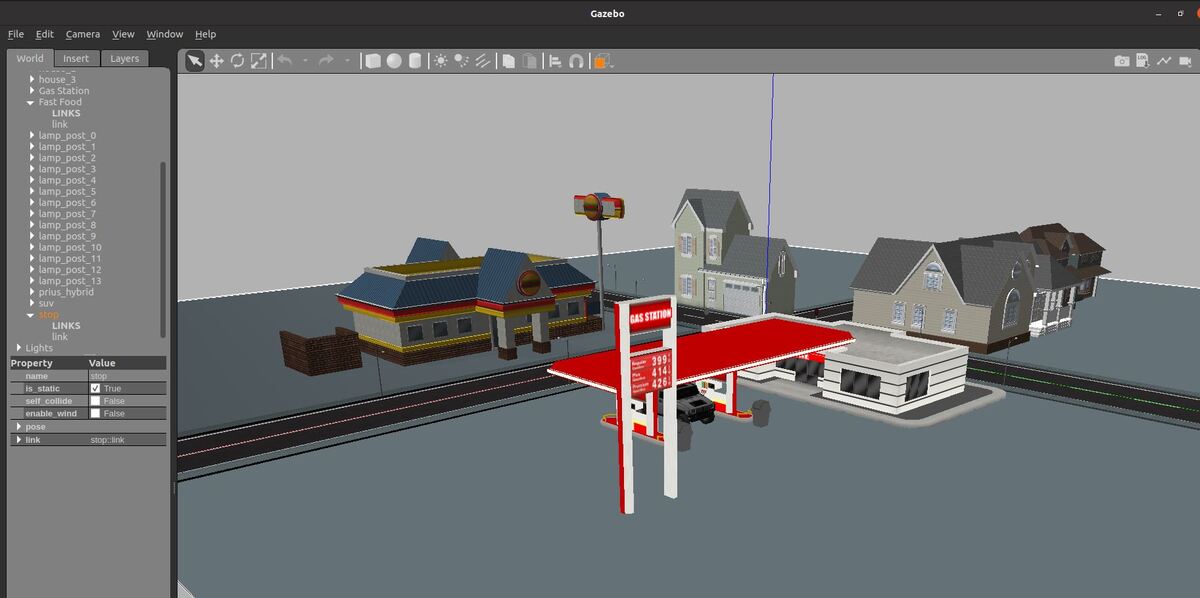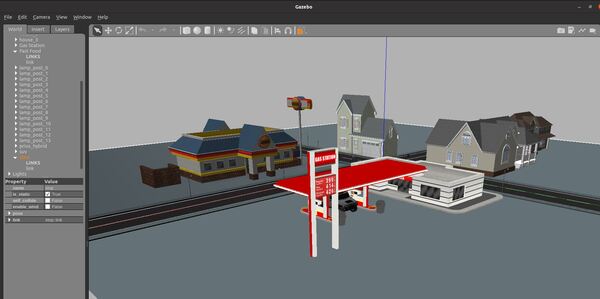
In this post, I will show you how to load an SDF file into Gazebo. Simulation Description Format (SDF) is the standard Gazebo format for robot modeling.
If you would like to learn more about SDF files, check out this page.
Prerequisites
- ROS 2 Foxy Fitzroy installed on Ubuntu Linux 20.04 or newer. I am using ROS 2 Galactic, which is the latest version of ROS 2 as of the date of this post.
- You have already created a ROS 2 workspace. The name of our workspace is “dev_ws”, which stands for “development workspace.”
- (Optional) You have a package named two_wheeled_robot inside your ~/dev_ws/src folder, which I set up in this post. If you have another package, that is fine.
- (Optional) You know how to load a world file into Gazebo using ROS 2.
You can find the files for this post here on my Google Drive.
Create the SDF File
I am going to open up a terminal window, and type the following command to go to the directory where my SDF file will be located.
cd ~/dev_ws/src/two_wheeled_robot/models
Add the folder for the model into this directory. The name of my folder is two_wheeled_robot_description. You can find the folder here on my Google Drive.
Launch the Model Manually
To launch the model manually, you will need to go to your bashrc file and add the path to the model so that Gazebo can find it.
Open a terminal window, and type:
gedit ~/.bashrc
Add the following line to the bottom of the file:
export GAZEBO_MODEL_PATH=$GAZEBO_MODEL_PATH:/home/focalfossa/dev_ws/src/two_wheeled_robot/models
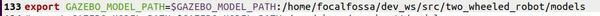
Save the file and close it.
Open Gazebo.
gazebo
Click Insert in the top left.
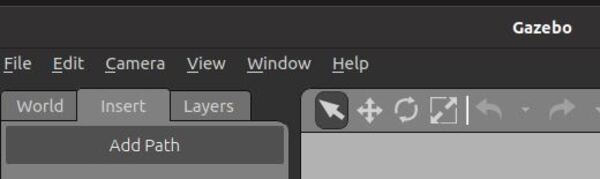
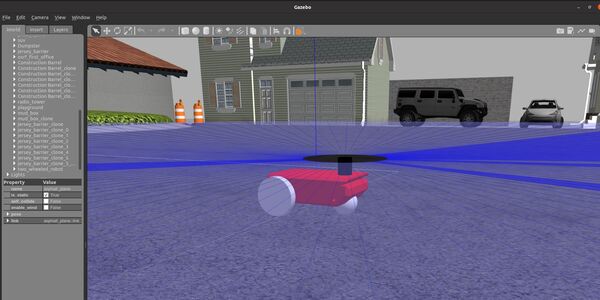
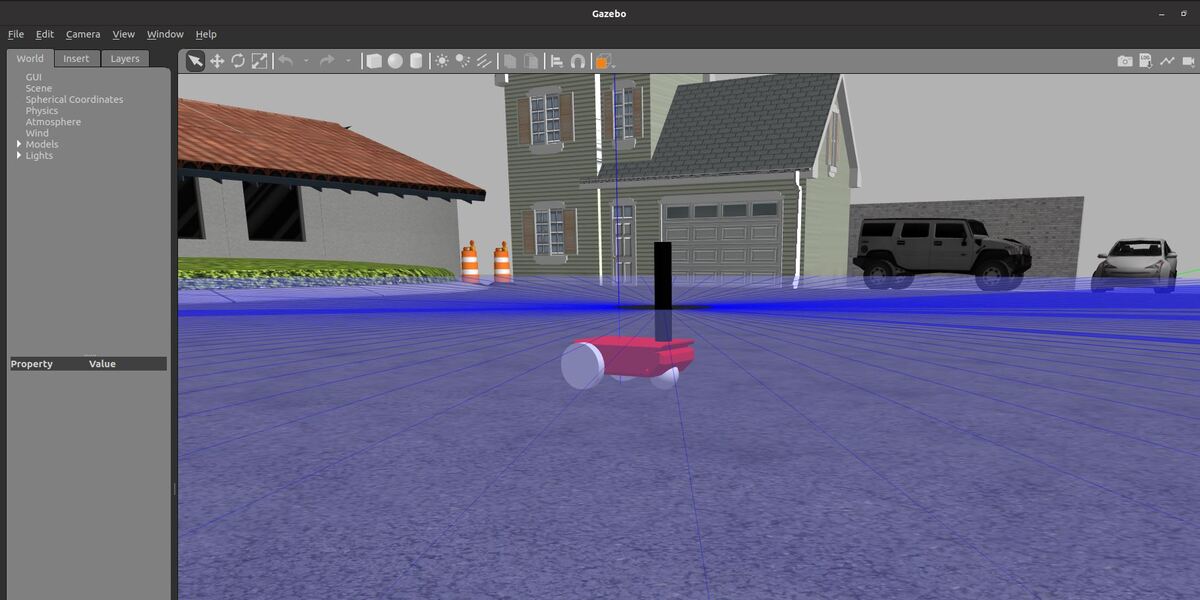
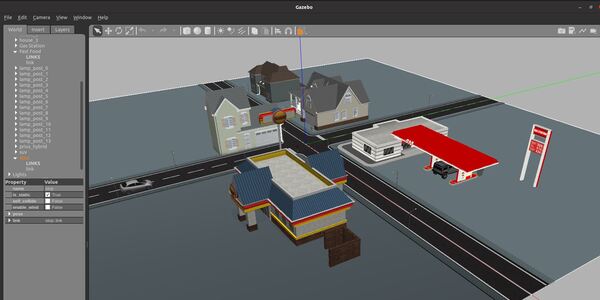
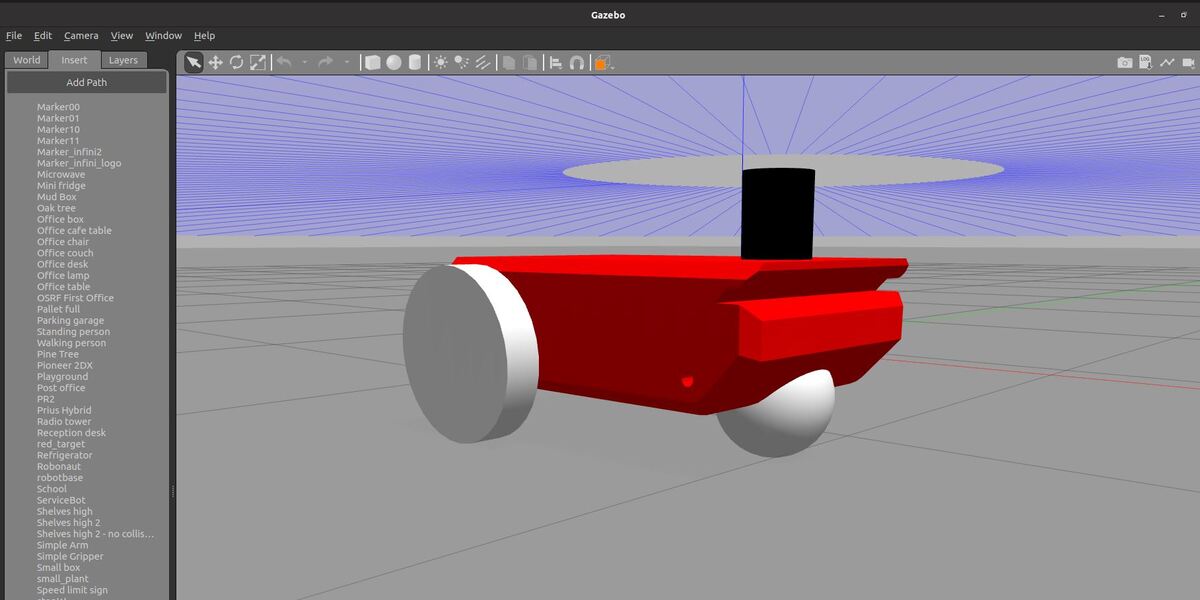
I will scroll down until I find “Two Wheeled Robot”. I click on the robot and place it inside the Gazebo empty world.

Here is what it looks like:
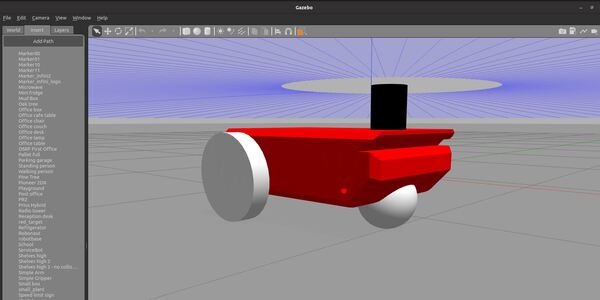
Press CTRL+C in all windows to close everything down.
Launch the Model Automatically
Now I want to launch the model automatically.
Create the Launch File
Now we want to create a launch file.
I am going to go to my launch folder and create the file. Here is the command I will type in my terminal window.
cd ~/dev_ws/src/two_wheeled_robot/launch
gedit launch_sdf_into_gazebo.launch.py
Type the following code inside the file.
# Author: Addison Sears-Collins
# Date: September 27, 2021
# Description: Load an SDF and world file into Gazebo.
# https://automaticaddison.com
import os
from launch import LaunchDescription
from launch.actions import DeclareLaunchArgument, ExecuteProcess, IncludeLaunchDescription
from launch.conditions import IfCondition, UnlessCondition
from launch.launch_description_sources import PythonLaunchDescriptionSource
from launch.substitutions import Command, LaunchConfiguration, PythonExpression
from launch_ros.actions import Node
from launch_ros.substitutions import FindPackageShare
def generate_launch_description():
# Constants for paths to different files and folders
gazebo_models_path = 'models'
package_name = 'two_wheeled_robot'
robot_name_in_model = 'two_wheeled_robot'
sdf_model_path = 'models/two_wheeled_robot_description/model.sdf'
world_file_path = 'worlds/neighborhood.world'
# Pose where we want to spawn the robot
spawn_x_val = '0.0'
spawn_y_val = '0.0'
spawn_z_val = '0.0'
spawn_yaw_val = '0.0'
############ You do not need to change anything below this line #############
# Set the path to different files and folders.
pkg_gazebo_ros = FindPackageShare(package='gazebo_ros').find('gazebo_ros')
pkg_share = FindPackageShare(package=package_name).find(package_name)
world_path = os.path.join(pkg_share, world_file_path)
gazebo_models_path = os.path.join(pkg_share, gazebo_models_path)
os.environ["GAZEBO_MODEL_PATH"] = gazebo_models_path
sdf_model_path = os.path.join(pkg_share, sdf_model_path)
# Launch configuration variables specific to simulation
gui = LaunchConfiguration('gui')
headless = LaunchConfiguration('headless')
namespace = LaunchConfiguration('namespace')
sdf_model = LaunchConfiguration('sdf_model')
use_namespace = LaunchConfiguration('use_namespace')
use_sim_time = LaunchConfiguration('use_sim_time')
use_simulator = LaunchConfiguration('use_simulator')
world = LaunchConfiguration('world')
# Declare the launch arguments
declare_namespace_cmd = DeclareLaunchArgument(
name='namespace',
default_value='',
description='Top-level namespace')
declare_use_namespace_cmd = DeclareLaunchArgument(
name='use_namespace',
default_value='false',
description='Whether to apply a namespace to the navigation stack')
declare_sdf_model_path_cmd = DeclareLaunchArgument(
name='sdf_model',
default_value=sdf_model_path,
description='Absolute path to robot sdf file')
declare_simulator_cmd = DeclareLaunchArgument(
name='headless',
default_value='False',
description='Whether to execute gzclient')
declare_use_sim_time_cmd = DeclareLaunchArgument(
name='use_sim_time',
default_value='true',
description='Use simulation (Gazebo) clock if true')
declare_use_simulator_cmd = DeclareLaunchArgument(
name='use_simulator',
default_value='True',
description='Whether to start the simulator')
declare_world_cmd = DeclareLaunchArgument(
name='world',
default_value=world_path,
description='Full path to the world model file to load')
# Start Gazebo server
start_gazebo_server_cmd = IncludeLaunchDescription(
PythonLaunchDescriptionSource(os.path.join(pkg_gazebo_ros, 'launch', 'gzserver.launch.py')),
condition=IfCondition(use_simulator),
launch_arguments={'world': world}.items())
# Start Gazebo client
start_gazebo_client_cmd = IncludeLaunchDescription(
PythonLaunchDescriptionSource(os.path.join(pkg_gazebo_ros, 'launch', 'gzclient.launch.py')),
condition=IfCondition(PythonExpression([use_simulator, ' and not ', headless])))
# Launch the robot
spawn_entity_cmd = Node(
package='gazebo_ros',
executable='spawn_entity.py',
arguments=['-entity', robot_name_in_model,
'-file', sdf_model,
'-x', spawn_x_val,
'-y', spawn_y_val,
'-z', spawn_z_val,
'-Y', spawn_yaw_val],
output='screen')
# Create the launch description and populate
ld = LaunchDescription()
# Declare the launch options
ld.add_action(declare_namespace_cmd)
ld.add_action(declare_use_namespace_cmd)
ld.add_action(declare_sdf_model_path_cmd)
ld.add_action(declare_simulator_cmd)
ld.add_action(declare_use_sim_time_cmd)
ld.add_action(declare_use_simulator_cmd)
ld.add_action(declare_world_cmd)
# Add any actions
ld.add_action(start_gazebo_server_cmd)
ld.add_action(start_gazebo_client_cmd)
ld.add_action(spawn_entity_cmd)
return ld
Save the file and close it.
Build the Package
Go to the root folder.
cd ~/dev_ws/
Build the package.
colcon build
Launch the Launch File
Now let’s launch the launch file.
cd ~/dev_ws/
ros2 launch two_wheeled_robot launch_sdf_into_gazebo.launch.py
Here is the output: