In this post, I’ll show you how to configure your Raspberry Pi so that your programs can run as soon as you plug in your Raspberry Pi to a power source.
Requirements
Here are the requirements:
Run a program as soon as the Raspberry Pi is turned on.
Directions
Power up your Raspberry Pi, and open up a terminal window.
Type:
sudo nano /etc/rc.local
Scroll down the file to the area right after fi but before exit 0. Type:
python3 /home/pi/robot/ball_following_yellow.py &
The format is
python3 /your/file/path/here/filename.py &
Press CTRL-X, and save the file.
Restart your Raspberry Pi.
sudo reboot
Your program, ball_following_yellow.py, should run on startup.
In this tutorial, I will show you how to give your wheeled robot the ability to follow a colored ball. You will get your first taste of computer vision and image processing.
Special shout out to Matt Timmons-Brown for this project idea. He is the author of a really good book on Raspberry Pi robotics: (Learn Robotics with Raspberry Pi). Go check it out!
Video
Here is a video of what we will build in this tutorial.
Requirements
Here are the requirements:
Build a wheeled robot powered by Raspberry Pi that must identify and follow a yellow rubber ball using OpenCV, a library of programming functions for real-time computer vision and image processing.
You Will Need
The following components are used in this project. You will need:
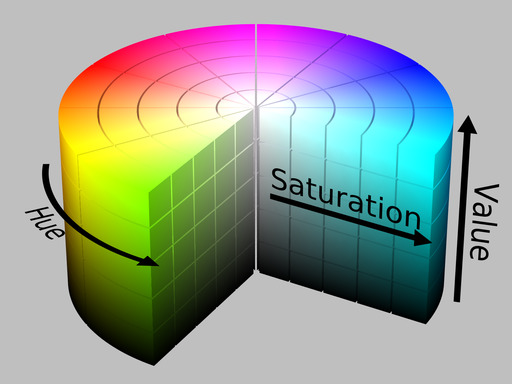
We need to select an appropriate HSV (hue, saturation, value) value for the yellow ball. HSV is an alternative color representation that is frequently used instead of the RGB (Red Green Blue) color model I covered in my light and sound wheeled robot post.
Here is the HSV table.
Since the ball is yellow, I’ll choose 60 as my starting number.
Open IDLE in your Raspberry Pi, and create a new file in your robot directory. Name it color_tester.py.
Here is the code for the program:
# Code source (Matt-Timmons Brown): https://github.com/the-raspberry-pi-guy/raspirobots
# import the necessary packages
from picamera.array import PiRGBArray
from picamera import PiCamera
import time
import cv2
import numpy as np
# initialize the camera and grab a reference to the raw camera capture
camera = PiCamera()
camera.resolution = (640, 480)
camera.framerate = 32
rawCapture = PiRGBArray(camera, size=(640, 480))
while True:
while True:
try:
hue_value = int(input("Hue value between 10 and 245: "))
if (hue_value < 10) or (hue_value > 245):
raise ValueError
except ValueError:
print("That isn't an integer between 10 and 245, try again")
else:
break
lower_red = np.array([hue_value-10,100,100])
upper_red = np.array([hue_value+10, 255, 255])
for frame in camera.capture_continuous(rawCapture, format="bgr", use_video_port=True):
image = frame.array
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
color_mask = cv2.inRange(hsv, lower_red, upper_red)
result = cv2.bitwise_and(image, image, mask= color_mask)
cv2.imshow("Camera Output", image)
cv2.imshow("HSV", hsv)
cv2.imshow("Color Mask", color_mask)
cv2.imshow("Final Result", result)
rawCapture.truncate(0)
k = cv2.waitKey(5) #& 0xFF
if "q" == chr(k & 255):
break
Place your ball about a yard in front of the camera.
Run the newly created program.
python3 color_tester.py
Choose 60.
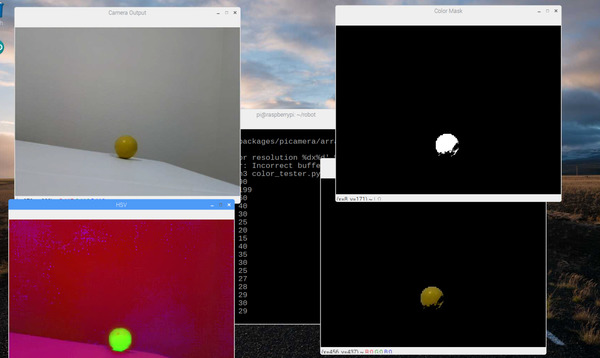
You will see four windows.
Window 1. RGB representation
Window 2: HSV representation
Window 3: Show the portions of the frame that match a hue value of 60.
Window 4: Entire frame minus all portions that do NOT have a 60 hue value.
To try a different hue value, select any of the four windows above. Press Q to halt the output of the video.
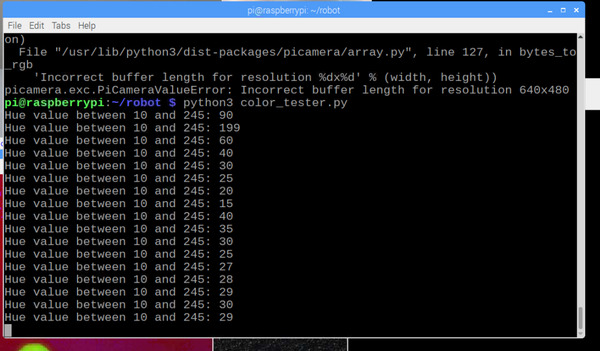
Go to the terminal window, and try a new hue valve. I’ll try 29 this time. It worked!
You keep trying different numbers until Window 4 shows mostly your ball and nothing else. Be patient and try LOTS of numbers.
Write down the hue value you ended up with on a sheet of paper.
Press CTRL-C in the terminal window to stop running color_tester.py.
Coding the Ball-Following Program
Open IDLE. Create a new file in your robot directory named:
ball_following_yellow. py
Here is the code (Credit to Matt Timmons-Brown, the author of a really good book on Raspberry Pi robotics: (Learn Robotics with Raspberry Pi):
Special shout out to Matt Timmons-Brown for this project idea. He is the author of a really good book on Raspberry Pi robotics: (Learn Robotics with Raspberry Pi). Go check it out!
Video
Here is a video of what we will build in this tutorial.
Requirements
Here are the requirements:
Build a line-following robot using Raspberry Pi.
You Will Need
The following components are used in this project. You will need:
These sensors have an infrared (IR) receiver and transmitter.
Black things (e.g. black electrical tape) absorb IR light; white things (e.g. white poster board) reflect IR light.
The receiver will not be able to detect IR light emitted by the transmitter when the robot is over the black electrical tape. Output (OUT pin) of the sensor will be LOW.
The receiver will detect IR light emitted (and then reflected) by the transmitter when the robot is on top of the white poster board because the white poster board will reflect the IR light (black will absorb the IR light). The output (OUT pin) of the sensor will go HIGH.
The robot will use the information provided by this sensor to steer itself and follow the black electrical tape line.
Connect the VCC pin of the IR line sensor to pin 1 of the Raspberry Pi.
Connect the GND pin of the line sensor to the blue (negative) ground rail of the solderless breadboard.
Connect the OUT pin of the line sensor to pin 21 (GPIO 9) of the solderless breadboard.
Testing the Infrared Line Sensor
Power up your Raspberry Pi, and open IDLE.
Create a new program called test_line_following.py.
Save it in to your robot directory.
Here is the code:
import gpiozero
import time
# Description: Code for testing the
# TCRT5000 IR Line Track Follower Sensor
# Author: Addison Sears-Collins
# Date: 05/29/2019
# Initialize line sensor to GPIO9
line_sensor = gpiozero.DigitalInputDevice(9)
while True:
if line_sensor.is_active == False:
print("Line detected")
else:
print("Line not detected")
time.sleep(0.2) # wait for 0.2 seconds
Create a line-following course using your black electrical tape and your poster board. It should look something like this.
I recommend leaving a 3-inch margin between the side of the poster board and the course. Don’t make curves that are too sharp.
Run your test program from a terminal window.
cd robot
python3 test_line_following.py
Move your track in front of the sensor to see if the terminal prints out “Line detected. “
If you are running into issues, use a screwdriver to adjust the sensitivity of the sensor.
That white and blue potentiometer is what you should tweak.
Connect the other IR line sensor.
Connect the VCC pin of the IR line sensor to pin 17 of the Raspberry Pi using a female-to-female jumper wire.
Connect the GND pin of the IR line sensor to the blue (negative) ground rail of the solderless breadboard.
Connect the OUT pin of the IR line sensor to pin 23 (GPIO 11) of the Raspberry Pi.
Attaching the Sensors
Attach the first IR line sensor you wired up to the front, left side of the robot.
Attach the second IR line sensor to the right side of the robot.
Both sensors need to be just off the ground and can be mounted using 2×2 Lego blocks that extend downward from the body of the robot.
A piece of VELCRO is sufficient to attach both sensors.
Run the wires connected to the IR line sensors down through the gap in the robot body.
Create the Line-Following Program in Python
Open IDLE on your Raspberry Pi.
Create a new file inside your robot directory named
line_following_robot.py
Here is the code:
import gpiozero
# File name: line_following_robot.py
# Code source (Matt-Timmons Brown): https://github.com/the-raspberry-pi-guy/raspirobots
# Date created: 5/29/2019
# Python version: 3.5.3
# Description: Follow a line using a TCRT5000 IR
# Line Following Sensor
robot = gpiozero.Robot(left=(22,27), right=(17,18))
left = gpiozero.DigitalInputDevice(9)
right = gpiozero.DigitalInputDevice(11)
while True:
if (left.is_active == True) and (right.is_active == True):
robot.forward()
elif (left.is_active == False) and (right.is_active == True):
robot.right()
elif (left.is_active == True) and (right.is_active == False):
robot.left()
else:
robot.stop()
Deploying Your Line-Following Robot
Place your robot on your track. Make sure the line-following sensors are directly above the black line.
Verify that your Raspberry Pi is connected to battery power, and your 4xAA battery pack is turned on.
Run your program from inside the robot directory.
cd robot
python3 line_following_robot.py
Watch your robot follow the line! Press CTRL-C anytime to stop the program.