

The foundation of ROS 2 communication is made up of three elements, publishers, subscribers, and topics.
Let’s use an analogy to explain these three elements.
Imagine our robot is like a superhero team with lots of helpers. Each helper has a special superpower, like seeing far away with LIDAR, seeing close-up with the camera, and detecting nearby objects with the ultrasonic sensor.
Publishers are like the robot’s messengers. They take the information from each helper (like the distance LIDAR measured or the picture the camera saw) and shout it out loud on a special channel called a topic. Think of it like a walkie-talkie channel just for robot information!
Subscribers are like the robot’s listeners. They tune into the topic and listen for the messages the publishers shout. When they hear something, they understand what it means and tell the robot what’s happening around it. For example, if the LIDAR subscriber hears “Obstacle 5 meters ahead!” the robot knows to stop.
So, the publisher is the one who shares the information, the subscriber is the one who listens and learns, and the topic is the special channel they use to talk to each other. This way, all the robot’s helpers can work together and keep it safe and aware of its surroundings, just like a superhero team!
Remember, just like superheroes have different powers, publishers and subscribers have different jobs, but they all work together to make the robot super smart.
Publishers and subscribers are functionalities within processes called nodes. Nodes are the fundamental building blocks of a ROS 2 system, each representing an independent unit of computation with specific tasks.
Nodes:
- Individual processes that perform specific tasks within a ROS 2 system.
- Each node has a unique name and can host multiple publishers and subscribers.
- Nodes communicate with each other through topics.
Publishers:
- Functionalities within a node that publish data via topics.
- Topics are named channels like “sensor_data” or “motor_commands” where data is published and made available to interested subscribers.
- Any node can subscribe to a topic, regardless of the publisher node.
Subscribers:
- Functionalities within a node that receive data published to a topic.
- They can process the received data and utilize it for their specific tasks.
- Multiple subscribers can listen to the same topic simultaneously.
Here is a graphic from the ROS 2 website that puts all this together.
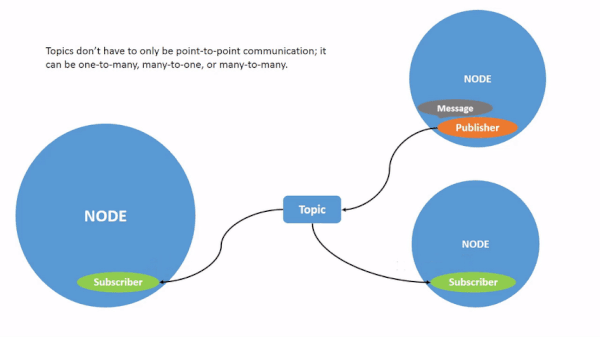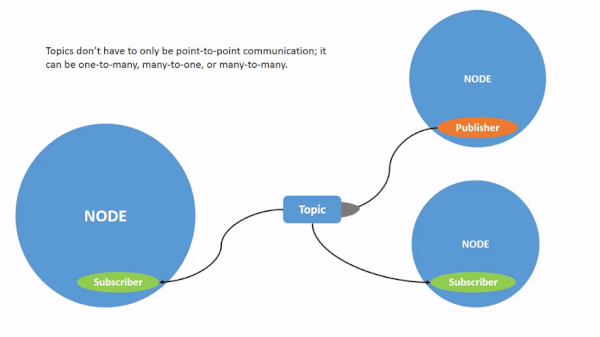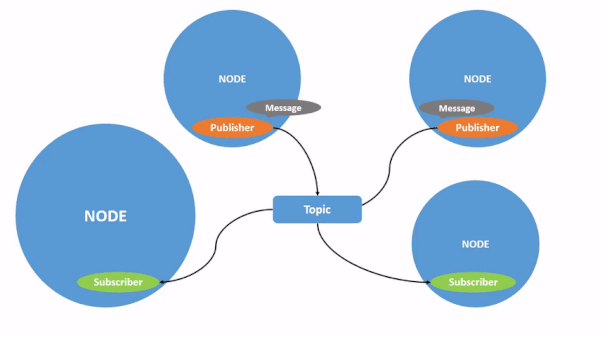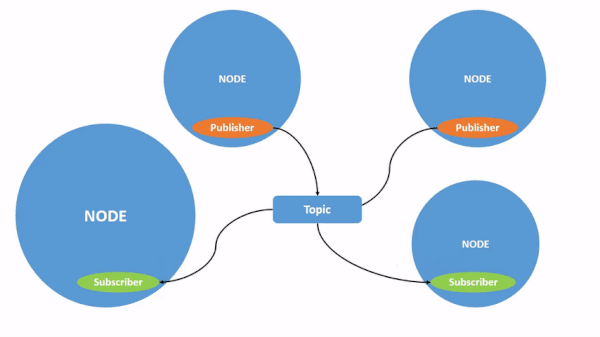
You don’t need to memorize the information above. Just refer back to it whenever you get confused on the ROS 2 jargon.
Keep building!


{kind=link}