

With all of the different machine learning models out there (unsupervised learning, supervised learning, and reinforcement learning), how do you go about deciding which model to use for a particular problem?
One approach is to try every possible machine learning model, and then to examine which model yields the best results. The problem with this approach is it could take a VERY long time. There are dozens of machine learning algorithms, and each one has different run times. Depending on the data set, some algorithms may take hours or even days to complete.
Another risk of doing the “try-all-models” approach is that you also might end up using a machine learning algorithm on a type of problem that is not really a good fit for that particular algorithm. An analogy would be like using a hammer to tighten a screw. Sure, a hammer is a useful tool but only when used for its intended purpose. If you want to tighten a screw, use a screwdriver, not a hammer.
When deciding on what type of machine learning algorithm to use, you have to first understand the problem thoroughly and then decide what you want to achieve. Here is a helpful framework that can be used for algorithm selection:
Are you trying to divide an unlabeled data set into groups such that each group has similar attributes (e.g. customer segmentation)?
If yes, use a clustering algorithm (unsupervised learning) like k-means, hierarchical clustering, or Gaussian Mixture Models.
Are you trying to predict a continuous value given a set of attributes (e.g. house price prediction)?
If yes, use a regression algorithm (supervised learning), like linear regression.
Are we trying to predict discrete classes (e.g. spam/not spam)? Do we have a data set that is already labeled with the classes?
If yes to both questions, use a classification algorithm (supervised learning) like Naive Bayes, K-Nearest Neighbors, logistic regression, ID3, neural networks, or support vector machines.
Are you trying to reduce a large number of attributes to a smaller number of attributes?
Use a dimensionality reduction algorithm, like stepwise forward selection or principal components analysis.
Do you need an algorithm that reacts to its environment, continuously learning from experience, the way humans do (e.g. autonomous vehicles and robots)?
If yes, use reinforcement learning methods.
For each of the questions above, you can ask follow-up questions to hone in on the appropriate algorithm to use on that type.
For example:
- Do we need an algorithm that can be built, trained, and tested quickly?
- Do we need a model that can make fast predictions?
- How accurate does the model need to be?
- Is the number of attributes greater than the number of instances?
- Do we need a model that is easy to interpret?
- How scalable a model do we need?
- What evaluation criteria is important in order to meet business needs?
- How much data preprocessing do we want to do?
Here is a really useful flowchart from Microsoft that presents different ways to help one to decide what algorithm to use when:
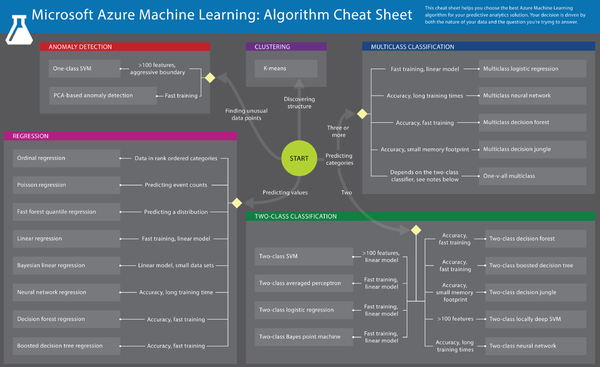
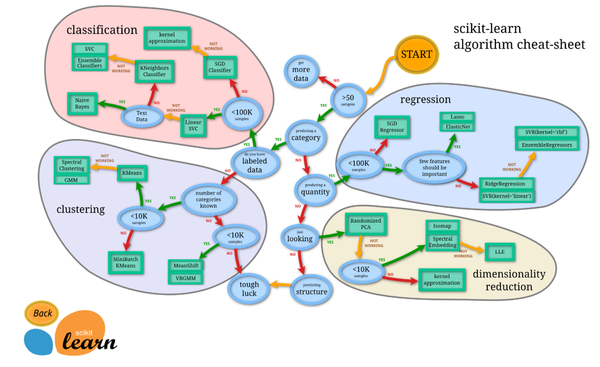
Here is another useful flowchart from SciKit Learn.
Slide 11 of this link shows the interpretability vs. accuracy tradeoffs for the different machine learning models.
This link provides a quick rundown of the different types of machine learning models.