

In this post, I will explain the concept of a maximum spanning tree.
What is a Spanning Tree?
Let’s say we have a graph G with three nodes, A, B, and C. Each node represents an attribute. For example, for a classification problem for breast cancer, A = clump size, B = blood pressure, C = body weight.
Graph G:
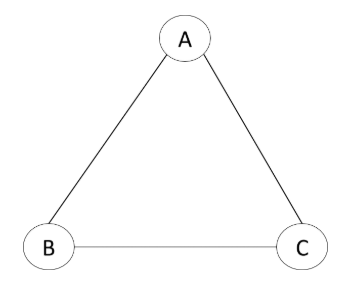
A spanning tree is a subset of the graph G that includes all of the attributes with the minimum number of edges (that would have to be 2 because a tree with just one edge would only connect at most 2 attributes). In the graph above, there are three spanning trees. All spanning trees in this graph G must have the same number of attributes (3 in total) and edges (2 in total).
Spanning Tree 1:
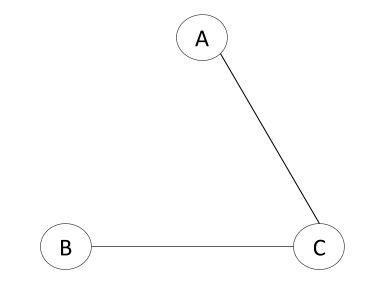
Spanning Tree 2:
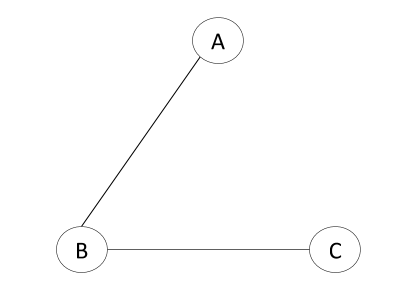
Spanning Tree 3:
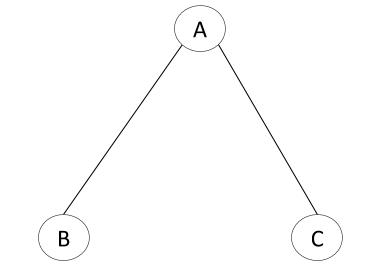
What is a Maximum Spanning Graph?
OK, so we have our spanning trees. Now, imagine that each edge has a weight. This weight would be some number. Weighted graphs look like this:
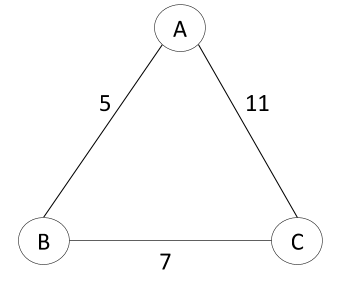
The graph above could has three spanning trees, subsets of the graph G that include all of the attributes with the minimum number of edges.
Which one of those spanning graphs is the “maximum spanning graph?”…the one that, when you add up the weights of each edge of the spanning graph, delivers the greatest result. The answer to that is our maximum spanning tree.
Here is the maximum spanning tree:
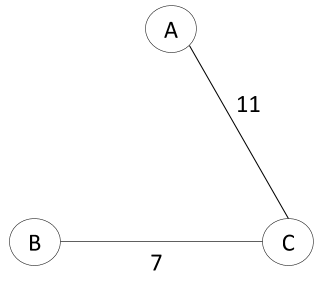
Since the Attribute Designated as the Root Is Arbitrary, Is It Safe to Assume That This Choice Does Not Affect the Model Effectiveness?
Yes, it is safe to assume that. The graph doesn’t change, and Kruskal’s algorithm, the algorithm for finding the maximum spanning tree in a graph doesn’t care what the root is…it just wants to find the largest edge at each step that doesn’t produce a cycle.
The number of maximum spanning trees in a graph G remains constant. Whether you start at C, B, and E, doesn’t matter. The graph is what it is…unless of course you decide to add a new attribute…but then it would be a different graph with a whole other set of spanning trees.