

In this blog post, we will take a look at the difference between maximum likelihood estimation and maximum a posteriori estimation. Both are methods that attempt to estimate unknown values for parameters.
What is Maximum Likelihood Estimation?
I will explain the term maximum likelihood estimation by using a real-world example.
Suppose you went out to the store and bought a six-sided die. You have no prior information about the type of die that you have. It could be a standard die which has a uniform prior probability distribution (i.e. each face has 1/6 chance of being face-up on any given roll), or you could have a weighted die where some numbers are more likely to appear than others. How would you calculate the probability of getting each number for a given roll of the die?
One way to calculate the probabilities is to roll the die 10,000 times and keep track of how many times (i.e. frequency in the table below) each face appeared. Your table might look something like this:
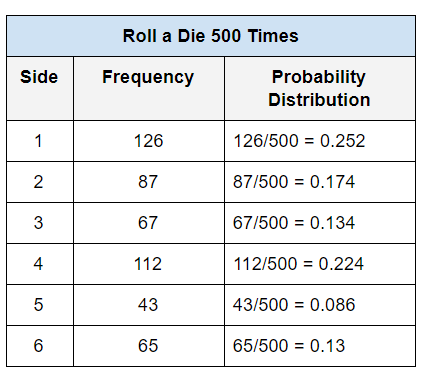
What you see above is the basis of maximum likelihood estimation. In maximum likelihood estimation, you estimate the parameters by maximizing the “likelihood function.” Stated more simply, you choose the value of the parameters that were most likely to have generated the data that was observed in the table above.
So, what is the problem with maximum likelihood estimation? Well, as you saw above, we did not incorporate any prior knowledge (i.e. prior belief information) into our calculation. What if we knew that this was a weighted die where the probabilities of each face were as follows:
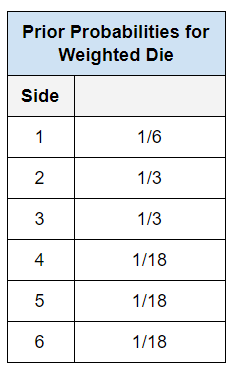
Maximum likelihood estimation does not take this into account. It assumes a uniform prior probability distribution. That is, it assumes that the probabilities of each face of the die are equal before we begin rolling the die 500 times. The problem with this assumption is that you would need to have a huge dataset (i.e. have to roll the die many times, perhaps until your arm gets too tired to continue rolling!) to get values for the appropriate probabilities that are close to what they should be.
More formally, maximum likelihood estimation looks like this:
Parameter = argmax P(Observed Data | Parameter)
where P = probability and | = given.
So what do we do? Maximum a posteriori (MAP) estimation to the rescue!
What is Maximum a Posteriori (MAP) Estimation?
Maximum a Posteriori (MAP) Estimation is similar to Maximum Likelihood Estimation (MLE) with a couple major differences. MAP takes prior probability information into account.
For example, if we knew that the die in our example above was a weighted die with the probabilities noted in the table in the previous section, MAP estimation factors this information into the parameter estimation.
More formally, MAP estimation looks like this:
Parameter = argmax P(Observed Data | Parameter)P(Parameter)
where P = probability and | = given.
Contrast that equation above to the MLE equation from the previous section. Note that the likelihood is now weighted by the prior probability. This distinction is important.
Imagine in MLE if we did 500 rolls, and one of the faces appeared only one time (i.e. 1/500). MLE would generate incorrect parameter values. Having that extra nonzero prior probability factor makes sure that the model does not overfit to the observed data in the way that MLE does.
Why Is Maximum a Posteriori (MAP) Estimation the Ideal Estimation Method for Smaller Datasets?
It is ideal because it takes into account prior knowledge of an event. MLE does not and is prone to overfitting. For this reason, MAP is considered a regularization of MLE. Adding the prior probability information reduces the overdependence on the observed data for parameter estimation.