In this section, we will work with the turtlesim application. This application comes pre-installed with ROS and consists of a 2D simulation of a turtle. You can move the turtle around and do a lot of other cool stuff as described here at the turtlesim ROS Wiki page.
Turtlesim isn’t the most exciting application, but it is a popular tool for learning the basics of ROS before working with real robots. You can think of the turtle as an actual robot. All of the things you can do with this turtle, you can do with a real, physical robot.
You Will Need
In order to complete this tutorial, you will need:
Directions
Let’s run this program now with rospy, the Python library for ROS.
Let’s launch turtlesim now. Open up a new terminal window, and type:
roscore
Open a new terminal tab, and launch the turtlesim application.
rosrun turtlesim turtlesim_node
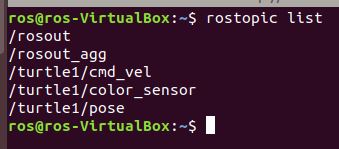
Let’s see the list of topics. Remember that a topic in ROS is a named bus (or channel) over which a node publishes messages for other nodes to receive. Open a new terminal tab, and type:
rostopic list
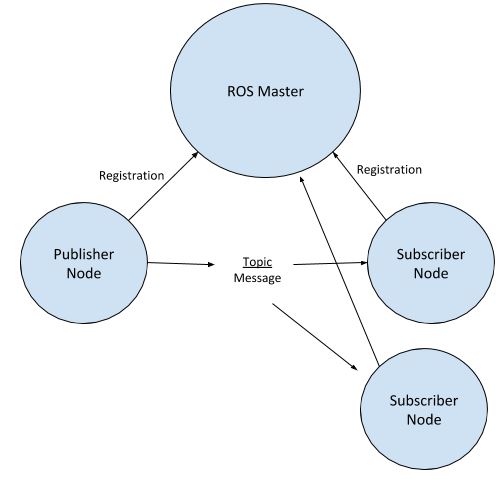
Now, up until now, the model that I have shown you of how ROS nodes communicate with each other is the ROS Topics model, in which a Publisher Node sends messages via a Topic to one or more registered Subscriber nodes. We worked with this model in the Hello World project in the previous section. This model looks like this:
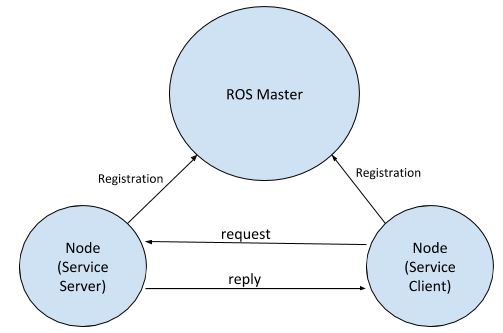
Notice that the flow of information between nodes is one-way, from Publisher to Subscriber. What do we do in a situation where we have a node that wants to request information from another node and receive an immediate reply? How is this two-way communication implemented in ROS? Request/reply in ROS is performed via ROS Services.
A ROS Service consists of a pair of messages: one for the request and one for the reply. A service-providing ROS node (i.e. Service Server) offers a service (e.g. read sensor data). A client node (i.e. Service Client) calls the service by sending a request message to the service provider. The client node then awaits the reply. Here is what the ROS Service model looks like:
The ROS tutorials present a good explanation of when you would want to use the ROS Topic model and when you would want to use the ROS Service model.
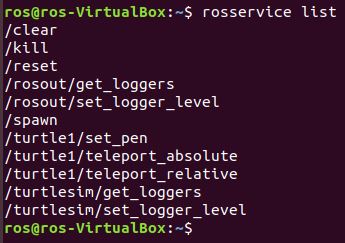
Now that we understand what a ROS Service is, let’s see a list of all active services in our turtlesim application. Open a new terminal window and type:
rosservice list
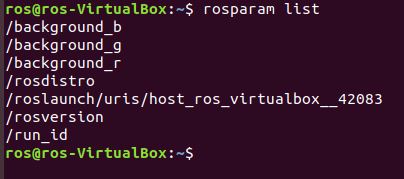
Let’s see a list of ROS parameters. Think of parameters as the global settings for our current ROS environment (e.g. things like the background color of the turtlesim screen, version of ROS we are using, etc.).
rosparam list
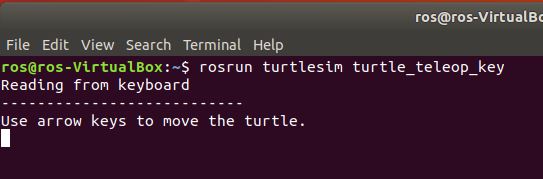
OK, now that we have covered some more ROS terminology, let’s have some fun and make this turtle move around the blue window. In order to do that, I need to create another ROS node. I have to open up a new terminal tab and type this command:
rosrun turtlesim turtle_teleop_key
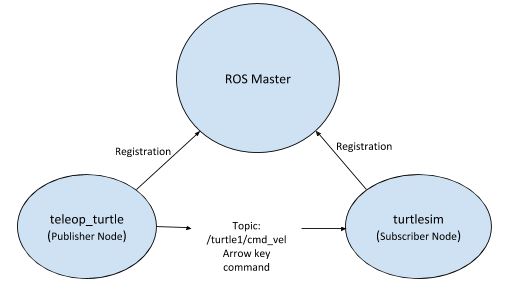
If you use the arrow keys on your keyboard from within the terminal where you typed the command above, you should see the turtle moving around the screen. Each time you press an arrow key, the teleop_turtle node publishes a message to the /turtle1/cmd_vel topic. turtlesim node is subscribed to that topic. It receives the message and moves the turtle.
Open a new terminal window and see a list of active nodes using this command:
rosnode list
Here is the block diagram of our application:
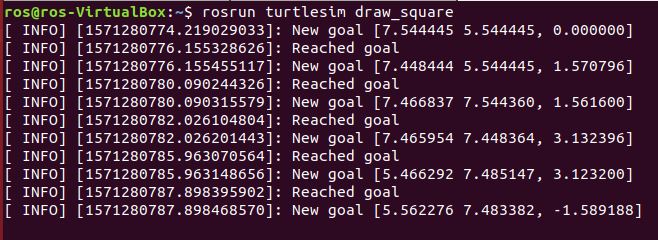
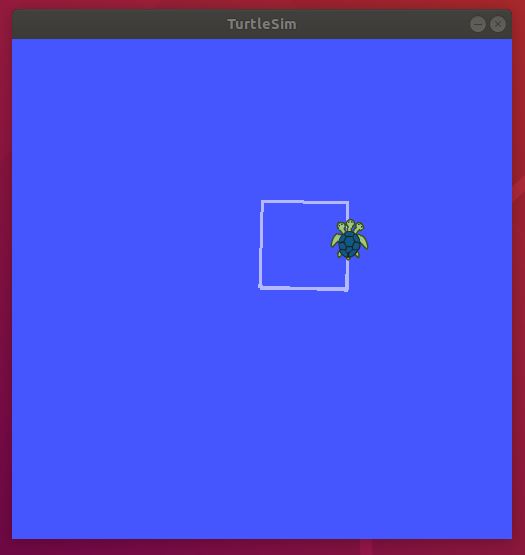
Now draw a square with turtlesim. Press Ctrl+C to stop the simulation. Close all terminal windows, and start a new terminal window. Type:
roscore
rosrun turtlesim turtlesim_node
rosrun turtlesim draw_square
The robot will go around and around along a square-shaped path.
To reset the simulator, type:
rosservice call /reset
Then type:
rosrun turtlesim draw_square
And now you have seen how to launch and run Turtlesim in ROS!