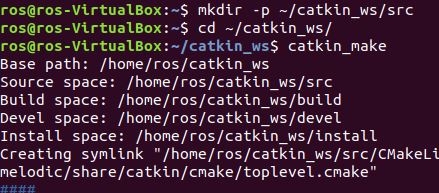
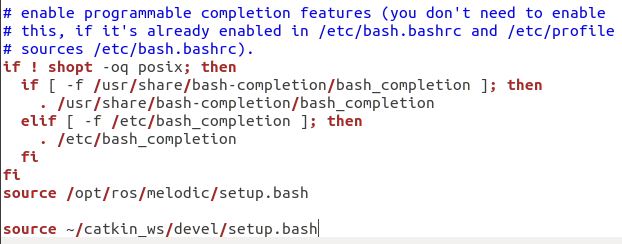
One way to execute a program in ROS it to launch one node at a time. In fact, that is exactly what we did in my previous post. This is fine if we have just two nodes, but what do we do if we have multiple nodes? Launching each node one-by-one can get inefficient really quickly.
Fortunately, ROS has a tool called roslaunch that enables you to launch multiple nodes all at once. Let’s do that now.
Directions
The first thing we need to do is to open a new terminal window and go to the hello_world package (or whatever package you want to launch).
cd catkin_ws/src/hello_world
Create a folder called ‘launch’.
mkdir launch
Create a new launch file inside the launch directory you just made.
cd launch
Open up the text editor.
gedit
Type the code below into the file, and save it. I’m going to save mine as talker_listener.launch. Save this file to the catkin_ws/src/hello_world/launch folder. This file will run C++ executables.
<launch>
<node name="listener_node" pkg="hello_world" type="listener" output="screen"/>
<node name="talker_node" pkg="hello_world" type="talker" output="screen"/>
</launch>
Note in the code above, if we are running a Python script, you will put the name of the script between the double quotes after type=. For example, if we want the launch file to run code named example.py, that line of the launch file code would look like this:
<node name="listener_node" pkg="hello_world" type="example.py" output="screen"></node>And, to make sure the ROS launch file can find the code, we have to make sure we change the permissions of the Python script before we execute the launch file. The code for doing this would be as follows:
chmod +x example.py
Open up a new terminal window, and type:
cd catkin_ws/src/hello_world/launch
Change the permissions of the launch file we just created. It will ask you for your password.
sudo chmod +x talker_listener.launch
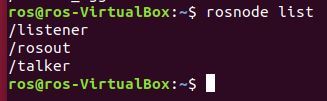
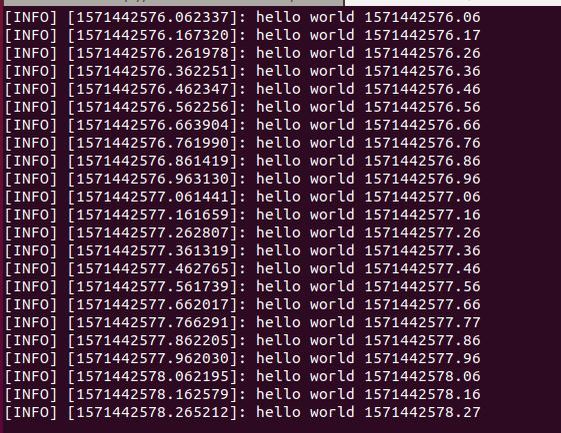
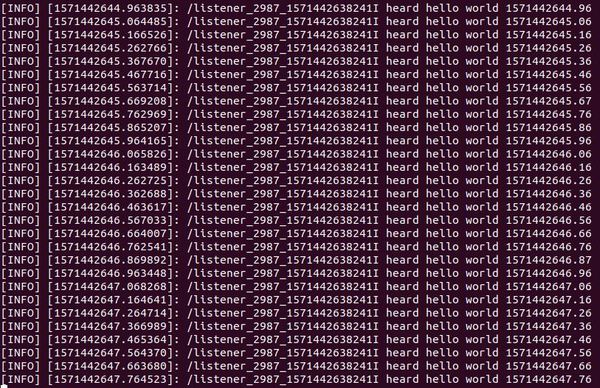
Run the launch file. Note that roslaunch automatically starts up roscore, so you don’t need to type roscore.
roslaunch hello_world talker_listener.launch
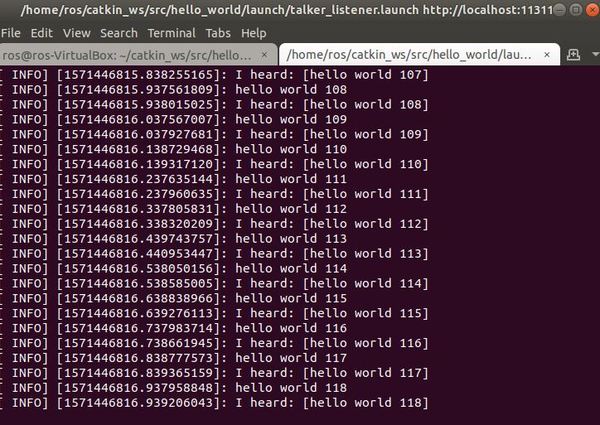
Press CTRL+C on your keyboard to stop the processes.
Now let’s create a launch file that launches the python nodes, talker.py and listener.py. I created these nodes in this tutorial. Open up the text editor.
gedit
Type the code below into the file, and save it as talker_listener_python.launch. Save this file to the catkin_ws/src/hello_world/launch folder.
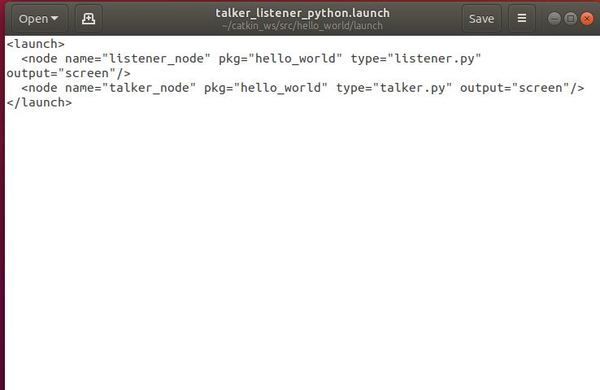
<launch>
<node name="listener_node" pkg="hello_world" type="listener.py" output="screen"/>
<node name="talker_node" pkg="hello_world" type="talker.py" output="screen"/>
</launch>
Open up a new terminal window, and type:
cd catkin_ws/src/hello_world/launch
Change the permissions of the launch file we just created. It will ask you for your password.
sudo chmod +x talker_listener_python.launch
Run the launch file.
roslaunch hello_world talker_listener_python.launch
Press CTRL+C on your keyboard to stop the processes.
There may be times when you try to run a launch file, and ROS isn’t able to locate a new package. To refresh the package list, you execute the following command.
rospack profile
That’s it! You’re all done.