

One of the disadvantages of k-means is that it is a local search (optimization) procedure. In order to explain what that means, I will do a quick overview of:
- How k-means works.
- The main disadvantage of local search procedures like k-means
- A real-world example of k-means and the local search problem
How K-means Works
The K-means algorithm is used to group unlabeled data sets into clusters based on similar attributes. It involves four main steps.
- Select k: Determine the number of clusters k you want to group your data set into.
- Select k Random Instances: You choose, at random, k instances from the data set. These instances are the initial cluster centroids.
- Cluster Assignment: This step involves going through each of the instances and assigning that instance to the cluster centroid closest to it.
- Move Centroid: You move each of the k centroids to the average of all the instances that were assigned to that cluster centroid.
Notice how k-means is a local search procedure. What this means is that at each step the optimal solution for each instance is the one that is the most local. Local search entails defining a neighborhood, searching for that neighborhood, and then proceeding based on the assumption that local is better…the neighboring centroid that is the closest is the best.
Why is Local Search a Disadvantage?
The problem with methods like k-means that make continuous local improvements to the solution is that they are at risk of “missing the forest for the trees.” They might be so focused on what is local, that they miss the obvious big picture.


To explain this point, I will present an example from the real world.
Real-world Example
Suppose we had data on the voting behavior, income level, and age for 10,000 people in Los Angeles, CA. We want to group these people into clusters based on similarities of these attributes. Without looking at the unlabeled data set, we think there should be three clusters (Republican, Democrat, and Independent). We decide to run k-means on the data set and select k=3.
Here is the unlabeled data set:
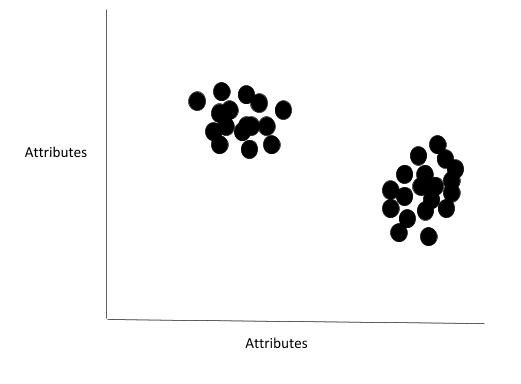
Here are the results after running k-means:
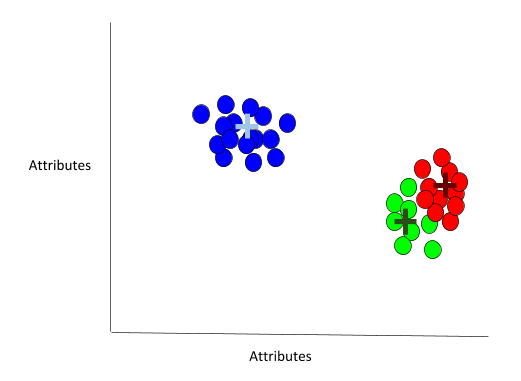
The algorithm has defined three clusters, each with its own centroid.
What is the problem with this solution? The problem is that our solution is stuck in local minima. It is obvious to the human eye that there are two clusters not three (blue = Democrats and red/green = Republicans). The red and green dots are really a single group. However, since k-means is a local search procedure, it optimizes locally.
We could run k-means 10,000 times, and the centroids would not move. The real centroid for those green and red points is somewhere between the green and red dots. However, k-means doesn’t know that. It just cares about finding the optimal local solution.
Globally, we can see k-means gave us incorrect clustering because it was so focused on what was good in the neighborhoods and could not see the big picture. An analogy is this graph below:
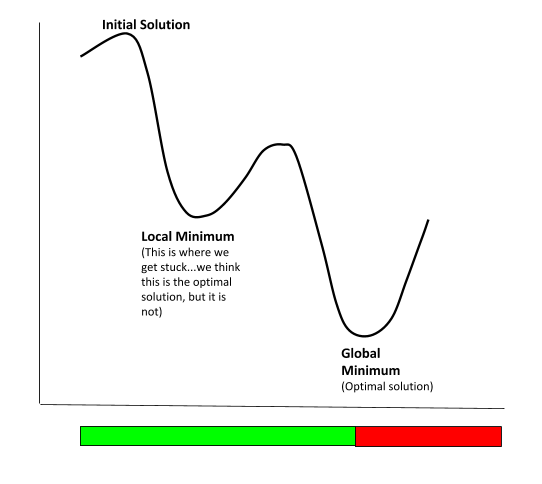
Since k-means is so sensitive to the initial choice of centroids as well as the value for k, it helps to have some prior knowledge of the data set, This knowledge will be invaluable to making sure the results of k-means make sense in the context of the problem.
Would local searching still be a potential issue if we had chosen k=2 in this case?
Yep! It would still be an issue depending on the choice of initial centroids. As I mentioned earlier, k-means is sensitive to the initial choice of centroids as well as the value for k. Choose bad starting centroids that gets the algorithm stuck in bad local optima, and you could run k-means 10,000 times, and the centroids would not budge.