

How to Build a C++ Node
Now that we’ve created our two nodes, we need to build them. Building ROS nodes means getting them in a format that enables ROS to use them.
The first thing we need to do is to edit the CMakeLists.txt file inside the noetic_basics_part_1 package.
The CMakeLists.txt file is the file inside the noetic_basics_part_1 package that was automatically generated when we created the package. CMakeLists.txt says how to build the code we wrote (i.e. the nodes we just created).
Let’s edit the CMakeLists.txt file for the noetic_basics_part_1 package. Open a new terminal window, and type this command:
roscd noetic_basics_part_1
gedit CMakeLists.txt
You should see a file that looks like this:
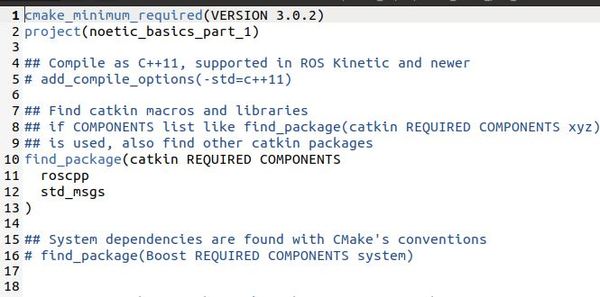
Now add these lines to the bottom of the CMakeLists.txt file:
add_executable(simple_publisher_node src/simple_publisher_node.cpp)
target_link_libraries(simple_publisher_node ${catkin_LIBRARIES})
add_executable(simple_subscriber_node src/simple_subscriber_node.cpp)
target_link_libraries(simple_subscriber_node ${catkin_LIBRARIES})
In the code above, we have done the following:
- Create two executables, simple_publisher_node and simple_subscriber_node, which will by default go into the ~/catkin_ws/devel/lib/noetic_basics_part_1 folder.
- Make sure the nodes get linked to the catkin libraries (i.e. ROS-related libraries).
Now save and close the CMakeLists.txt file.
Open a new terminal window, and type the following commands to build all the nodes in the noetic_basics_part_1 package:
cd ~/catkin_ws
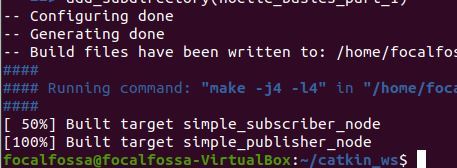
catkin_make
That command above will build all nodes inside all the packages in your catkin workspace.
Now, open a new terminal window and go to the catkin_ws/devel/lib/noetic_basics_part_1/ folder.
cd ~/catkin_ws/devel/lib/noetic_basics_part_1/
Type dir to see the files listed. You will see the publisher and subscriber executables. Feel free to close the terminal window now.

How to Build a Python Node
Navigate to the scripts folder inside your package.
roscd noetic_basics_part_1/scripts
Make the files executable. Type these commands, pressing Enter after each.
chmod +x simple_python_publisher.py
chmod +x simple_python_subscriber.py
Open a new terminal window, and type the following commands to build all the nodes in the noetic_basics_part_1 package:
cd ~/catkin_ws
catkin_make