

In this post, I will explain the difference between supervised and unsupervised learning.
Table of Contents
What is Supervised Learning?

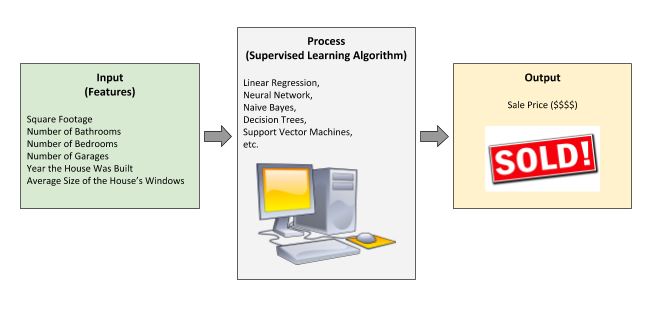
Imagine you have a computer. The computer is really good at doing math and making complex calculations. You want to “train” your computer to predict the price for any home in the United States. So you search around the Internet and find a dataset. The dataset contains the following information for 100,000 houses that sold during the last 30 days in various cities across the United States:
- Square footage
- Number of bathrooms
- Number of bedrooms
- Number of garages
- Year the house was constructed
- Average size of the house’s windows
- Sale price
Variables 1 through 6 above are the dataset’s features (also known as input variables, attributes, independent variables, etc.). Variable 7, the house sale price, is the output variable (or target variable) that we want our computer to get good at predicting.
So the question is…how do we train our computer to be a good house price predictor? We need to write a software program. The program needs to take as input the 100,000-house dataset that I mentioned earlier. This program needs to then find a mathematical relationship between variables 1-6 (features) and variable 7 (output variable). Once the program has found a relationship between the features (input) and the output, it can predict the sale price of a house it has never seen before.
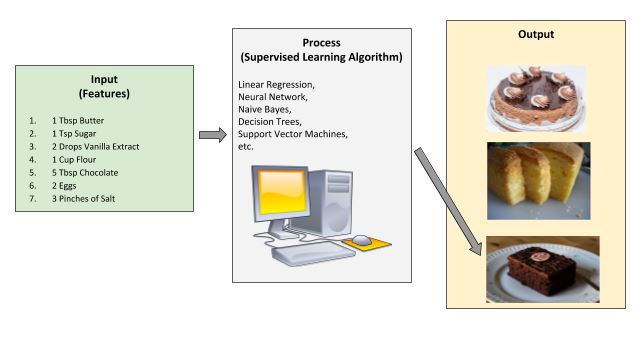
Let’s take a look at an analogy. Supervised learning is like baking a cake.
Suppose you had a cake machine that was able to cook many different types of cake from the same set of ingredients. All you have to do as the cake chef is to just throw the ingredients into the machine, and the cake machine will automatically make the cake.
The “features,” the inputs to the cake machine, are the following ingredients:
- Butter
- Sugar
- Vanilla Extract
- Flour
- Chocolate
- Eggs
- Salt
The output is the type of cake:
- Vanilla Cake
- Pound Cake
- Chocolate Cake
- Dark Chocolate Cake

Different amounts of each ingredient will produce different types of cake. How does the cake machine know what type of cake to produce given a set of ingredients?
Fortunately, a machine learning engineer has written a software program (containing a supervised learning algorithm) that is running inside the cake machine. The program was pre-trained on a dataset containing 1 million cakes. Each entry (i.e. example or training instance) in this gigantic dataset contained two key pieces of data:
- How much of each ingredient was used in the making of that given cake
- The type of cake that was produced
During the training phase of the program, the program found a fairly accurate mathematical relationship between the amount of each ingredient and the cake type. And now, when the cake machine is provided with a new set of ingredients by the chef, it automatically “knows” what type of cake to produce. Pretty cool huh!
What I described above is called supervised learning. It is called supervised learning because the input data (which the supervised learning algorithm used to train) is already labeled with the “correct” answers (e.g. the type of cake in our example above; or the sale price values for those 100,000 homes from the earlier example I presented in this post.). We supervised the learning algorithm by “telling” it what the output (cake type) should be for 1 million different sets of input values (ingredients).
The fundamental idea of a supervised learning algorithm is to learn a mathematical relationship between inputs and outputs so that it can predict the output value given an entirely new set of input values.
Let’s take a look at a common supervised learning algorithm: linear regression. The goal of linear regression is to find a line that best fits the relationship between input and output. For example, the learning algorithm for linear regression could be trained on square footage and sale price data for 100,000 homes. It would learn the mathematical relationship (e.g. a straight line in the form y = mx + b) between square footage and the sale price of a home.
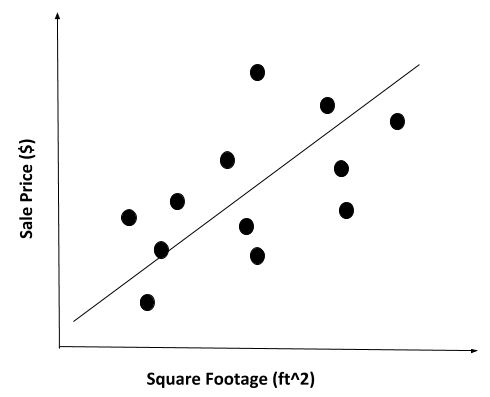
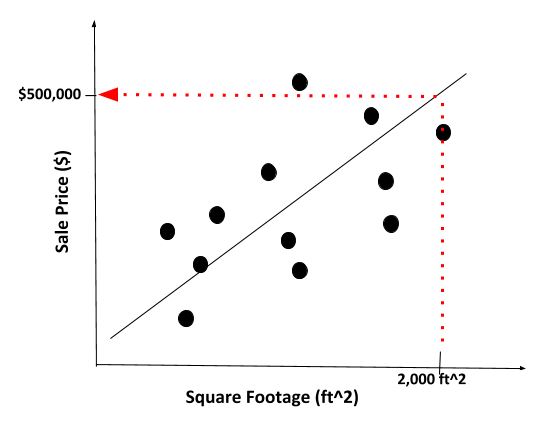
With this relationship (i.e. line of best fit) in hand, the algorithm can now easily predict the sale price of any home just by being provided with the home’s square footage value.
For example, let’s say we wanted to find the price of a house that is 2000 ft2. We feed 2,000 ft2 into the algorithm. The algorithm predicts a sale price of $500,000.
As you can imagine, before we make any predictions using a supervised learning algorithm, it is imperative to train it on a lot of data. Lots and lots of data. The more the merrier.
In the example above, to get that best fit line, we want to feed it with as many examples of houses as possible during training. The more data it has, the better its predictions will be when given new data. This, my friends, is supervised learning, and it is incredibly powerful. In fact, supervised learning is the bread and butter of most of the state-of-the-art machine learning techniques today, such as deep learning.
Now, let’s look at unsupervised learning.
What is Unsupervised Learning?
Let’s suppose you have the following dataset for a group of 13 people. For each person, we have the following features:
- Height (in inches)
- Hair Length (in inches)
Let’s plot the data to see what it looks like:
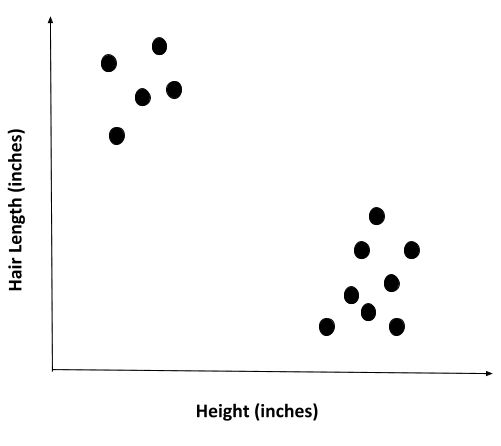
In contrast to supervised learning, in this case there is no output value that we are trying to predict (e.g. house sale price, cake type, etc.). All we have are features (inputs) with no corresponding output variables. In machine learning jargon, we say that the data points are unlabeled.
So instead of trying to force the dataset to fit a straight line or some sort of predetermined mathematical model, we let an unsupervised learning algorithm find a pattern all on its own. And here is what we get:
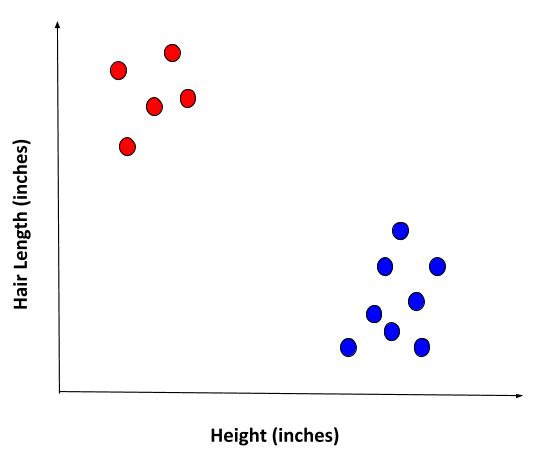
Aha! It looks like the algorithm found some sort of pattern in the data. The data is clustered into two distinct groups. What these clusters mean, we do not know because the data points are unlabeled. However, what we do suspect given our prior knowledge of this dataset, is that the blue dots are males, and the red dots are females given the attributes are height and hair length.
What I have described above is known as unsupervised learning. It is called unsupervised because the input dataset is unlabeled. There is no output variable we are trying to predict. There is no prior mathematical model we are trying to fit the data to. All we want to do is let the algorithm find some sort of structure or pattern in the data. We let the data speak for itself.
Any time you are given a dataset and want to group similar data points into clusters, you’re going to want to use an unsupervised learning algorithm.