In this post, I will discuss the difference between a mutex and a semaphore using a gas station bathroom analogy.
What is a Mutex?
A mutex (mutual exclusion object) grants exclusive access to shared data or computer hardware. It is like a bathroom key at a gas station. If you have the key, nobody else can enter the bathroom while you are using it. Only one person (task) can use the bathroom (shared resource) at a time.
If a person (task) wants to use the bathroom, he or she must first get the bathroom key (mutex) since there is only one copy. The gas station owner (operating system) is responsible for managing the bathroom key (mutex).
Continuing from our example in the previous section, imagine that there are two bathrooms (shared resources) instead of one. Also there are two bathroom keys instead of one. Since bathroom entry is no longer exclusive, this is not a mutex scenario. Instead, the keys are called semaphores.
A semaphore enables two or more (two in this example) tasks (people) to use a shared resource (gas station bathroom) simultaneously.
If two keys (semaphores) are available, the value of the semaphore is 2.
If one key is available, the value of the semaphore is 1.
If no keys are available, that means that two tasks (people) are currently working (in the bathroom). The value of the semaphore is 0. The next task (person) must wait until a semaphore becomes available (i.e. a task finishes, and the semaphore is incremented by 1).
What Technique of Protecting Shared Data Requires Less Overhead?
Answer: Semaphore
Overhead includes things like memory, bandwidth, and task execution time. If tasks are able to work on different copies of shared data, each individual task will undoubtedly perform its function with less overhead. There is no waiting in line or waiting for a semaphore to be released.
However, the operating system (gas station owner) will have more overhead. It will spend a lot of resources having to manage the different copies of data. In addition, relative to a mutex implementation, copying data and enabling concurrent processing of that data will require more memory and processing power.
In this post, I will discuss the tradeoffs of using the Round Robin, Round Robin with Interrupts, and Function Queue Scheduling approaches when building an embedded system. Let’s consider that we will use an Arduino to perform tasks such as capturing sensor data and downloading to a host machine (e.g. your personal laptop computer).
Round Robin
Definition
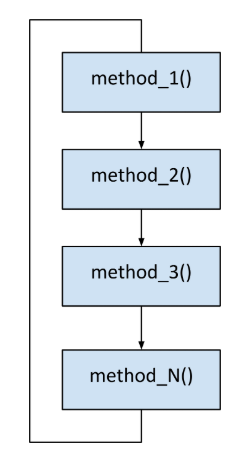
The Round Robin architecture is the easiest architecture for embedded systems. The main method consists of a loop that runs again and again, checking each of the I/O devices at each turn in order to see if they need service. No fancy interrupts, no fear of shared data…just a plain single execution thread that gets executed again and again.
Pros
Simplest of all the architectures
No interrupts
No shared data
No latency concerns
No tight response requirements
Cons
A sensor connected to the Arduino that urgently needs service must wait its turn.
Fragile. Only as strong as the weakest link. If a sensor breaks or something else breaks, everything breaks.
Response time has low stability in the event of changes to the code
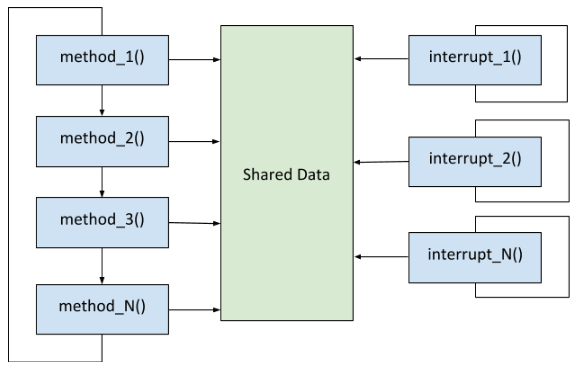
This Round Robin with Interrupts architecture is similar to the Round Robin architecture, except it has interrupts. When an interrupt is triggered, the main program is put on hold and control shifts to the interrupt service routine. Code that is inside the interrupt service routines has a higher priority than the task code.
Pros
Greater control over the priority levels
Flexible
Fast response time to I/O signals
Great for managing sensors that need to be read at prespecified time intervals
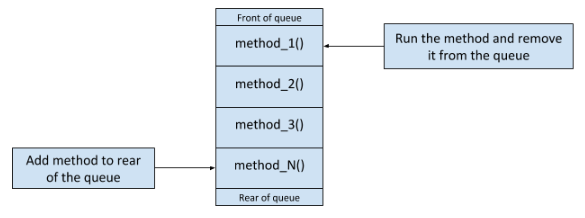
In the Function Queue Scheduling architecture, interrupt routines add function pointers to a queue of function pointers. The main program calls the function pointers one at a time based on their priority in the queue.
Pros
Great control over priority
Reduces the worst-case response for the high-priority task code
Response time has good stability in the event of changes to the code
Cons
Shared data
Low priority tasks might never execute (a.k.a. starving)
Before we discuss the shared data problem when building embedded systems, it is important to understand what interrupts are.
What are Interrupts?
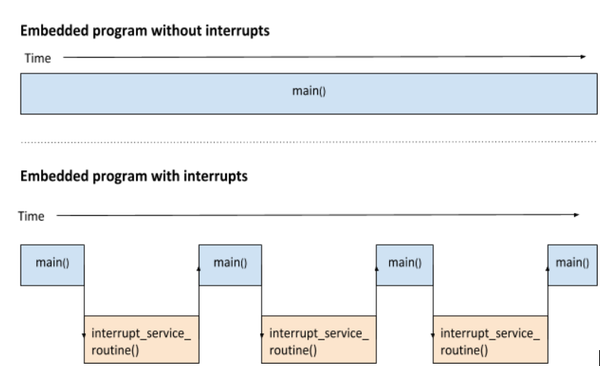
The most basic embedded software has a main program that runs uninterrupted…that is, it runs until either it stops on its own or something else causes it to stop.
For example, if you unplug your refrigerator, all programs that were running will immediately stop, and the refrigerator will shutdown. Otherwise, while the refrigerator is plugged in, programs will continue to run uninterrupted. This is called embedded software without interrupts.
You also have software where the main program executes normally but stops either periodically or due to some code (that is not part of the main method) that must get executed immediately. The main program stops, some other code is executed…(i.e. code that is not part of the main program). We call this an interrupt service routine. When this interrupt service routine is finished, control is shifted back to the main program, and the main program gets back to doing what is was doing prior to being interrupted.
Here is an image that shows what I just explained:
You likely trigger interrupt service routines all of the time without even knowing. For example, normally your desktop computer runs various background programs when you are not on your computer. Let’s call this the main() program. As soon as you click your mouse or type on your keyboard, you trigger an interrupt service routine. The computer handles this interrupt service routine by exiting the main() program temporarily, reading what you just did and doing what you commanded it to do (i.e. servicing the interrupt).
After that, the computer exits the interrupt service routine, goes back to doing what it was doing before you interrupted it (i.e. control shifts back to the main() program). That is a lot like how interrupts work in embedded systems, and you will find them in many if not most embedded programs in some form or fashion.
A big problem in embedded systems occurs in embedded software when an interrupt service routine and the main program share the same data. What happens if the main program is in the middle of doing some important calculations using some piece of data…an interrupt occurs that alters that piece of data…and then the main program finishes its calculation? Oops! The calculation performed by the main program might be corrupted because it is based off the wrong/different data value. This is known as the shared data problem.
Real-World Analogy: Running a Bakery
Imagine you own a bakery. You are trying to calculate how much money you made in 2018. You have just entered the revenue for each month listed in a Google spreadsheet. It looks like this:
Starting with January through March, you add the first three months of revenue into your calculator “10000 + 10000 + 10000 +” and then all of a sudden, your assistant (whose job it is to keep revenue updated periodically), interrupts you and asks if he can update something in the spreadsheet. You say, “Sure.”
You get up from your chair and go to the break room.
In the meantime, your assistant (i.e. the “interrupt service routine”) then gets on your computer.
While you are in the break room, your assistant changes the revenue on your spreadsheet in January 2018, increasing it from $10,000 to $15,000. He then leaves the room.
You then return from the break room. You get back in your chair and continue entering in the numbers in your calculator for the other nine months, for April through December. You conclude that the revenue for 2018 was $10000 per month for 12 months (i.e. $120,000). You record that number so that you can use it for your tax filings. Oops! See the mistake?
The main program (i.e. you) was unaware that the interrupt service routine (i.e. your assistant) made a change to the January 2018 revenue data, so the value of $120,000 is not consistent with the updated data. It should be $125,000 not $120,000.
This in a nutshell is the shared data problem. We need to make sure that you, the main() program, are NEVER interrupted while you are in the middle of making important calculations on your calculator. You and your assistant both share responsibility for making sure revenue is accurate, but we need to make sure you both aren’t working on the revenue at the same time.
In the real world, this would take the form of you posting a “DO NOT DISTURB” sign on your door to keep your assistant out when you are making critical calculations. In software engineering, we call this “disabling interrupts.” While interrupts are disabled, nothing can interrupt the main program.
Disabling interrupts is like the main program putting up a big DO NOT DISTURB sign. Source: Wikimedia Commons
Real-World Example: Designing an Automatic Doggy Door
Let’s look at a real-world example to further show you the shared data problem.
Problem
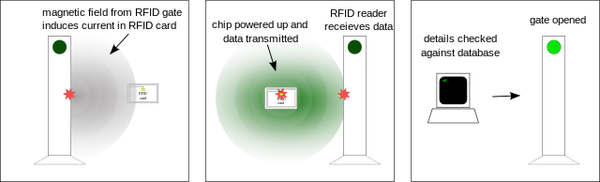
Imagine you are a software engineer working at a company. Your team is responsible for designing an automatic dog entry door. This embedded device can be wirelessly updated with RFID tags for dogs or other pets to be allowed entry.
The door needs to automatically unlock for dogs that are in the vicinity of the door. A pet must be allowed to enter even when the table of RFID tags is being updated. The RFID tag IDs are shared data since the interrupt service routine that must update the tag IDs and the main() program that is responsible for automatically unlocking the door when dogs are in the vicinity both share and use this data. A problem will occur when the doggy door is in the middle of an RFID tag ID update when a dog needs to get through the door. We wouldn’t want to let the poor dog wait outside in the freezing cold while the device is in the middle of an RFID tag update!
How do we create a solution that solves the shared data problem? The RFID tags need to be updated regularly but that same data is needed regularly by the main() program to let dogs enter when they need to. Let’s solve this now.
System Requirements
Dogs wearing RFID tags/cards need to be able to enter the door (i.e. gate) when they get close to the doggy door.
This embedded device can be wirelessly updated with RFID tags.
Dogs or other pets must be allowed entry when they are in the vicinity of the door.
Dog must be allowed to enter even when the table of RFID tags is being updated.
RFID tag IDs are shared data which must be managed.
In the shared data problem for the doggy door controller, we need to make sure the dog can enter at all times while the RFID tags are being updated. Because this is a dog, it is unacceptable for the door to remain locked and keep a dog waiting.
Implementation
To solve this problem, I would design the following loop for the main program in pseudocode:
While (True)
// Begin Critical Section of Code - Can't Be Interrupted
Disable_interrupts()
Scan to see if dogs are in the area (i.e. RFID scan)
If a valid dog is in the area, unlock the door
Else, do nothing
// End Critical Section of Code That Can't Be Interrupted
Re-enable_interrupts()
Update RFID table (interrupt service routine)
// In the meantime, dog is walking through the door
Check if the door is unlocked
If the door is unlocked, delay 30 seconds to give
the dog sufficient time to enter
Make sure the doggy door is locked
Go back to the beginning of this loop
The above architecture satisfies the requirements and enables a dog to enter even when the table of RFID tags is in the middle of an update.