You might have seen my previous tutorial where we ran the built-in ROS turtlesim program. We are going to explore this application further in this tutorial.
Turtlesim isn’t the most exciting application, but it is a popular tool for learning the basics of ROS before working with real robots (Click here for more information on turtlesim from the official ROS website). You can think of the turtle as an actual robot. All of the things you can do with this turtle, you can do with a real, physical robot. Let’s get started!
Table of Contents
- Move the Turtle
- Get the Turtle’s Position
- Move the Turtle a Specific Distance
- Work With ROS Services and ROS Parameters
- Change the Background Color and Reset the Workspace
Directions
Move the Turtle
Let’s run turtlesim with rospy, the Python library for ROS.
Open up a new terminal window and type:
roscore
Start the turtlesim node by going to a new terminal window and typing:
rosrun turtlesim turtlesim_node
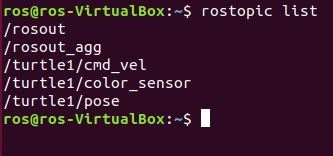
Open yet another terminal window and check out the list of topics that are currently active:
rostopic list
To move the turtle, we need to publish to the /turtle1/cmd_vel topic. But what type of messages can we publish to this topic? Let’s find out.
rostopic type /turtle1/cmd_vel
Here is the output:

What this means is that we need to publish messages of type geometry_msgs/Twist to the /turtle1/cmd_vel topic to get the turtle to move like we want it to.
So what does ‘geometry_msgs/Twist’ mean? We need to check out the definition of this data type.
rosmsg show geometry_msgs/Twist
The message you see on your terminal window expresses the velocity of the turtle in 3D space, broken into its linear and angular parts. With respect to the turtle, the two pieces of data that we can control are the linear velocity in the x-direction and the angular velocity along the z axis because the robot cannot move along either the z or y axes.
Check out this link at the ROS website if you want to dive into more detail about the different kinds of geometric data types, including Twist.
Let’s get the turtle moving. We need to create a node (i.e. program) and make sure that node publishes the velocity values to the /turtle1/cmd_vel topic. Let’s do that now.
Close out turtlesim using CTRL+C.
Open up a new terminal window and open the Linux text editor.
gedit
Type this Python code (credit to Lentin Joseph, author of Robot Operating System for Absolute Beginners).
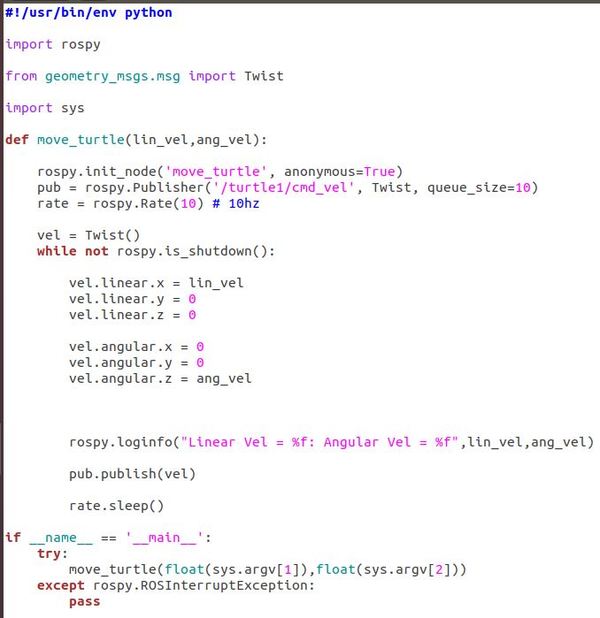
Save the file as move_turtle.py. Make sure to save it to your catkin_ws/src/hello_world/scripts folder.
The code above imports rospy (ROS library for Python), Twist (for us to work with the linear and angular velocity of the turtle), and sys (library that enables us to pass parameters via the Linux command line).
In a terminal window, type:
cd catkin_ws/src/hello_world/scripts
Make the node executable.
chmod +x move_turtle.py
chmod +x move_turtle.py
Open up a new terminal tab, launch ROS.
roscore
Open a new terminal tab, and launch the turtlesim node:
rosrun turtlesim turtlesim_node
Let’s get the turtle to move with a linear velocity of 3.0 m/s and an angular velocity of 1.5 radians/s. We need to pass those two values as arguments in the terminal. Open another terminal window and type:
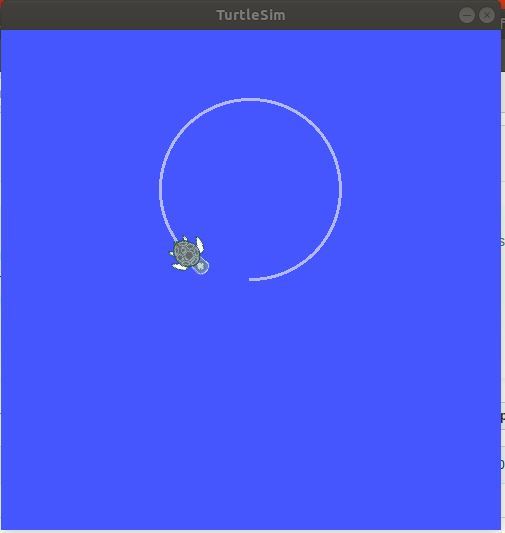
rosrun hello_world move_turtle.py 3.0 1.5
You should see the turtle moving in circles, around and around.
Open a new terminal window, and let’s see the ROS computation graph. Type this command:
rqt_graph
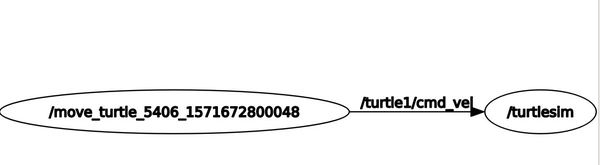
When you have had enough, stop the program by typing CTRL+C, and close all terminal windows.
Get the Turtle’s Position
Now that we know how to work with the velocity of the turtle, let’s take a look at how we can get the position of the robot. To do that, we need to work with the /turtle1/pose topic.
Launch ROS.
roscore
Start the turtlesim node by going to a new terminal window and typing:
rosrun turtlesim turtlesim_node
Let’s display the messages that are published to the /turtle1/pose topic.
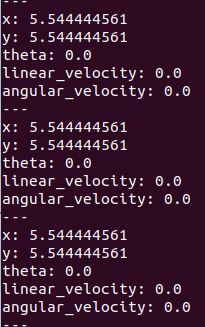
rostopic echo /turtle1/pose
Here is the output to the screen. You can see the position and velocity information.
We don’t want to have to type a command every time we want to get position and velocity information, so let’s modify move_turtle.py so that it subscribes to the /turtle1/pose topic.
First, find out what the message type is of the /turtle1/pose topic.
rostopic type /turtle1/pose
Let’s also get the message definition:
rosmsg show turtlesim/Pose
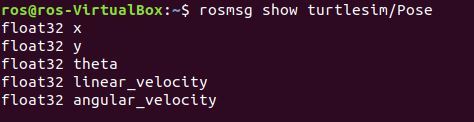
Press CTRL+C to stop the processes. You can exit all terminal windows.
Let’s get the pose using an actual Python-based node. Open up a new terminal window and open the Linux text editor.
gedit
Type this Python code (credit to Lentin Joseph, author of Robot Operating System for Absolute Beginners).
Save it as move_turtle_get_pose_.py to your catkin_ws/src/hello_world/scripts folder. Here is the code:
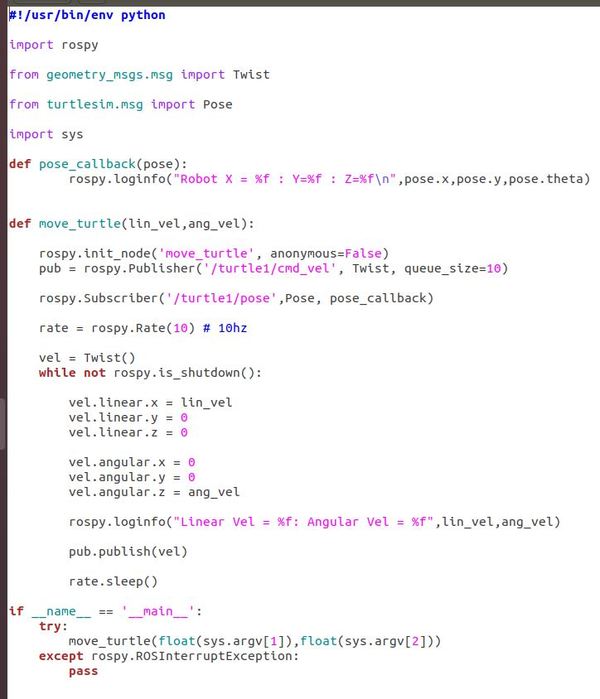
In a terminal window, type:
cd catkin_ws/src/hello_world/scripts
Make the node executable.
chmod +x move_turtle_get_pose_.py
chmod +x move_turtle_get_pose_.py
Open up a new terminal tab, launch ROS.
roscore
Open a new terminal tab, and launch the turtlesim node:
rosrun turtlesim turtlesim_node
Open a new terminal tab, and launch the move_turtle_get_pose node:
rosrun hello_world move_turtle_get_pose.py 1.0 0.5
You should see data output.
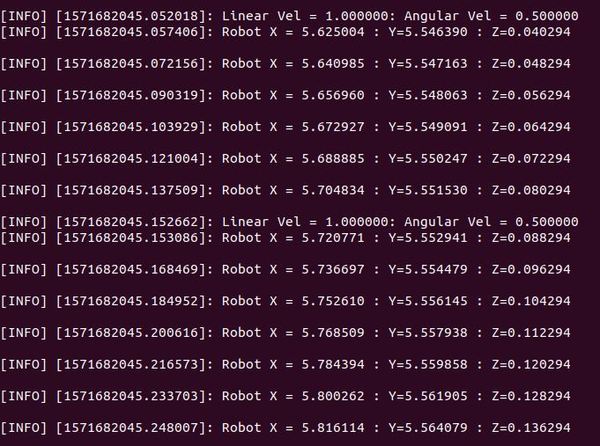
In a new terminal window, check out the computation graph:
rqt_graph
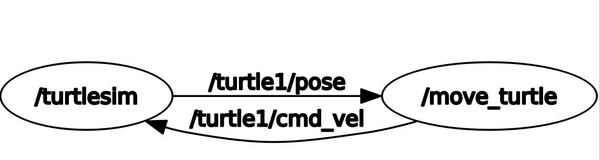
You can see that the move_turtle node is publishing position data to the /turtle1/pose topic. This topic is subscribed by the /turtlesim node. Similarly, the turtlesim node is publishing velocity data to the /turtle1/cmd_vel topic. This topic is being subscribed by the move_turtle node.
Press CTRL+C on all windows, and close the terminal screens.
Move the Turtle a Specific Distance
Now let’s move the turtle a distance that we specify.
Open up a new terminal window and open the Linux text editor.
gedit
Type this Python code (credit to Lentin Joseph, author of Robot Operating System for Absolute Beginners).
Save it as move_distance.py to your catkin_ws/src/hello_world/scripts folder. Here is the code:

In a terminal window, type:
cd catkin_ws/src/hello_world/scripts
Make the node executable. Type the command twice as sometimes you might get an error if you type it only once.
chmod +x move_distance.py
chmod +x move_distance.py
Open up a new terminal tab, launch ROS.
roscore
Open a new terminal tab, and launch the turtlesim node:
rosrun turtlesim turtlesim_node
Open a new terminal window, and launch the move_distance node. The arguments are linear velocity, angular velocity, and distance that you want the turtle to travel:
rosrun hello_world move_distance.py 0.4 0.0 7.0
Here is the data output:
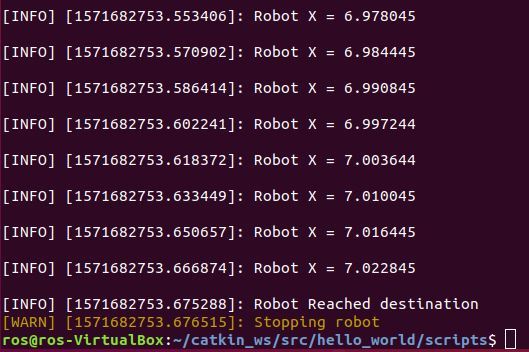
And here is what your simulation screen should look like:
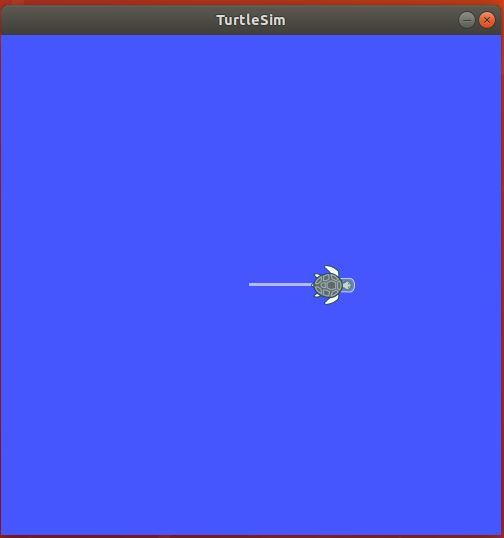
Press CTRL+C on all windows, and close the terminal screens.
Work With ROS Services and ROS Parameters
Ros Services
Up until now, we have been using what is called the publish/subscribe model for inter-node communication. A node publishes to a topic, and nodes that need the data published to that topic have to subscribe to that topic. This one-way communication model is flexible, but it is inefficient when we want two-way communication between nodes … for example if one node requests data from another node and wants a reply from that node.
Request / reply in ROS is done via what is known as a Service. A service is defined by a pair of messages: one for the request and one for the reply. If you want to know more details about ROS Services, check out this page on the ROS website.
Let’s check out a list of available ROS services in the turtlesim node. Open a new terminal window and type:
roscore
Start the turtlesim node by going to a new terminal tab and typing:
rosrun turtlesim turtlesim_node
Now in another terminal tab, type:
rosservice list
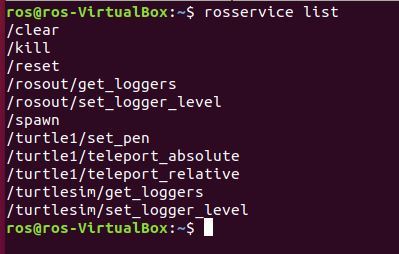
You should see this on your screen. We want to incorporate the reset service into our code. When the code calls the reset service, the workspace resets. Let’s find out the type of the reset service.
rosservice type /reset

stdsrvs/Empty is the type. It is a built-in service type in ROS. Let’s display some information on this service type.
rossrv show std_srvs/Empty

You can see that the field is empty. This is what we expected because no actual data is exchanged during this service. All the /reset service does is reset the workspace.
ROS Parameters
Before we implement the workspace reset service described above, let’s talk about what ROS parameters are.
Parameters are globally available values such as integers, floats, strings or booleans. We can also have parameters like background color.
Nodes (i.e. programs in C++/Python that exist inside ROS packages), can use parameters during runtime.
Parameters are stored inside the Parameter Server which is like a dictionary that contains the name of the parameter and the corresponding value of the parameter.
Let’s take a look at parameters in more detail now.
Open a new terminal tab and type the following command to retrieve a list of parameters:
rosparam list
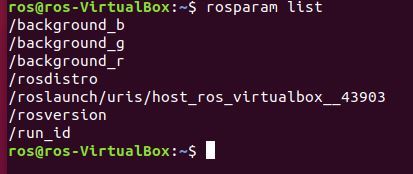
Let’s get the value of the red background color parameter, for example:
rosparam get /background_b

That’s how you retrieve the value of a parameter. The syntax is:
rosparam get <name_of_parameter>
If you would like to change the value of a parameter, you do that as follows:
rosparam set <name_of_parameter> <desired_value>
The topic of the background color parameter is /turtle1/color_sensor. Let’s see what this topic is all about by displaying some information on it:
rostopic echo /turtle1/color_sensor
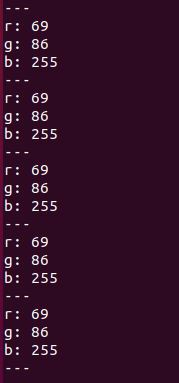
Press CTRL+C on all windows, and close the terminal screens.
Change the Background Color and Reset the Workspace
Let’s use some Python code that modifies the parameter for the background color and resets the workspace by calling the /reset service.
Open up a new terminal window and open the Linux text editor.
gedit
Type this Python code (credit to Lentin Joseph, author of Robot Operating System for Absolute Beginners).
Save it as turtle_service_param.py to your catkin_ws/src/hello_world/scripts folder.
In a terminal window, type:
cd catkin_ws/src/hello_world/scripts
Make the node executable.
chmod +x turtle_service_param.py
chmod +x turtle_service_param.py
Open up a new terminal tab, launch ROS.
roscore
Open a new terminal tab, and launch the turtlesim node:
rosrun turtlesim turtlesim_node
Open a new terminal tab, and launch the code:
rosrun hello_world turtle_service_param.py
Here is what your screen should look like:
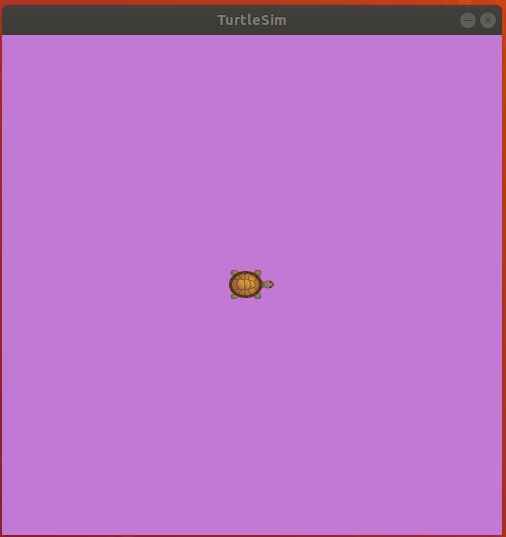
Here is what the terminal outputs:

If you press CTRL+C on the same terminal window, and then rerun this command, you will see we get a different color:
rosrun hello_world turtle_service_param.py
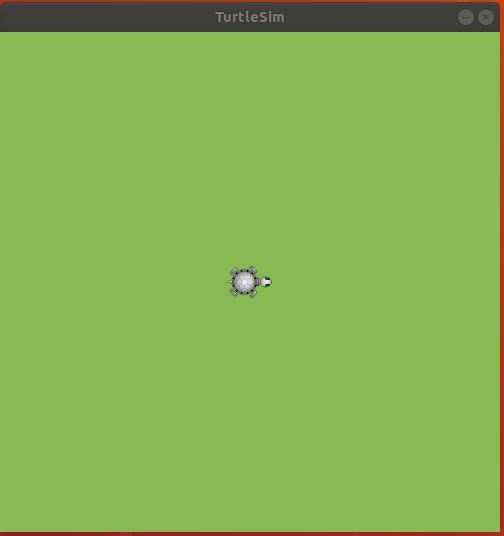
Each time you run the command above, you will get a message that the service has been executed.
When you are finished, press CTRL+C on all windows, and close the terminal screens.
Congratulations! You have completed the turtlesim tutorial.