
In machine learning, two-class classification problems are when we want to predict the class of an event given some attributes (e.g. spam/not spam, sick/not sick, pregnant/not pregnant, cancer/not cancer, etc.). We keep track of the prediction accuracy by constructing a confusion matrix and make a tally of the number of true positives, false positives, false negatives, and true negatives.
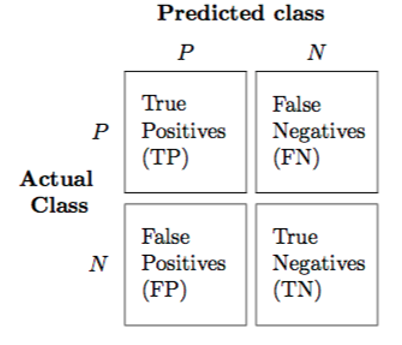
Here are some useful statistical metrics for two-class classification problems:
Accuracy: The proportion of all instances that are correctly predicted.
- Accuracy = (TP + TN)/(TP + TN + FP + FN)
Specificity: The proportion of actual negatives (i.e. 0) that were correctly predicted as such (e.g., the percentage of people who are healthy who were correctly predicted as being healthy).
- Specificity = (TN/(TN + FP))
Precision: The proportion of all positive predictions that were correct (e.g. the percentage of people who were predicted to have the disease and actually had the disease).
- Precision = (TP/(TP + FP))
Recall: The proportion of actual positives that were correctly identified as such (e.g., the percentage of people who have the disease who were correctly predicted to have the disease).
- Recall = (TP/(TP + FN))
Negative Predictive Value: The proportion of all negative predictions that were correct (e.g. the percentage of people who were predicted to be healthy who actually are healthy).
- Negative Predictive Value = (TN/(TN + FN))
Miss Rate: The proportion of actual positives that were predicted to be negative (e.g. the percentage of people who have the disease that were predicted to be healthy).
- Miss Rate = (FN/(FN + TP))
Fall-Out: The proportion of actual negatives that were predicted to be positive (e.g. the percentage of people who are healthy that were predicted to have the disease).
- Fall-Out = (FP/(FP + TN))
False Discovery Rate: The proportion of all positive predictions that were incorrect (e.g. the percentage of people who were predicted to have the disease that are actually healthy).
- False Discovery Rate = (FP/(FP + TP))
False Omission Rate: The proportion of all negative predictions that were incorrect (e.g. the percentage of people who were predicted to be healthy that actually have the disease).
- False Omission Rate = (FN / (FN + TN))
F1 Score: Measures prediction accuracy as a function of precision and recall. An F1 score of 1 is good…perfect precision and recall. An F1 score of 0 is bad, the worst-case precision and recall.
- F1 Score = ((2TP)/(2TP + FP + FN))